1. Overview - ML Projects - Full Stack Deep Learning
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Machine learning projects fail often in large companies; one cited survey reports 85% failure.
Briefing
Deep learning projects fail far more often than teams expect—one survey cited in the discussion found that 85% of AI projects at large companies fail—largely because machine learning still behaves more like research than a predictable engineering discipline. The central goal of the course is to push practitioners toward engineering habits: treating ML work as a lifecycle with clear activities, measurable progress, and realistic feasibility checks, rather than an open-ended experiment.
The discussion frames why failure is common. Some projects are technically infeasible, meaning the system never makes the jump from research prototypes into production reliability. Others lack clear success criteria from the start, so teams cannot tell whether they are improving or merely iterating. A third major failure mode is poor management of ML teams, which introduces challenges distinct from traditional software development.
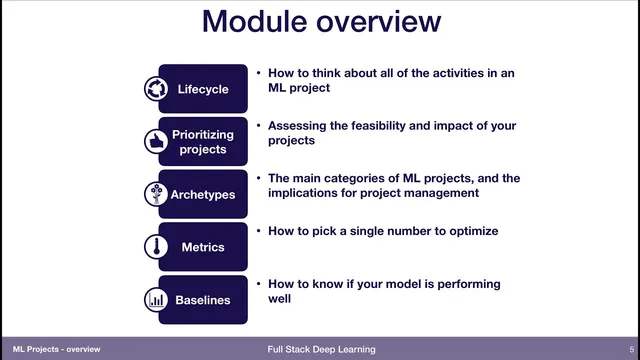
To address these issues, the lecture lays out a structured way to think about building production ML systems. It begins with the machine learning project lifecycle—mapping the full set of activities required to go from an idea to a deployed system. From there, it turns to prioritization: deciding whether a project is feasible and whether it is worth doing at all, before investing heavily in training runs and model experiments.
The session also introduces “archetypes” of machine learning projects—common patterns of ML work that help teams anticipate what kinds of risks and management implications they will face. Finally, it highlights two practical tools for getting started correctly: metrics and baselines. Metrics provide a single number (or tightly defined measurement) that captures what “better” means, while baselines establish reference performance so teams can judge whether a model is truly improving rather than drifting.
A running case study grounds the concepts in a concrete scenario: pose estimation for robotics. In the hypothetical setup, a robotics company trains a system that takes a single image as input and outputs an object’s position and orientation. The motivation is downstream utility: the pose estimates feed into a grasp model, which then decides how to grasp the object. The case study is used to illustrate how lifecycle planning, feasibility thinking, project archetypes, and the discipline of metrics and baselines apply to a real production-oriented ML pipeline—where success depends not only on model accuracy, but on whether the outputs can reliably support the next stage of the system.
Cornell Notes
Machine learning projects fail frequently—one cited survey reports 85% failure in large companies—because ML often remains closer to research than repeatable engineering. Many failures stem from technical infeasibility, unclear success criteria, and management practices that don’t fit ML’s unique constraints. The lecture proposes a more engineering-style approach: treat ML work as a lifecycle, prioritize projects by feasibility and value, and recognize common project archetypes to anticipate risks. It also emphasizes two setup fundamentals: define metrics as a single measurable target and use baselines to verify that improvements are real. A robotics pose-estimation case study (image → object position and orientation → grasp model) anchors these ideas in a production pipeline.
Why do so many AI/ML projects fail, according to the discussion?
What does “engineering discipline” mean in the context of ML projects?
How do metrics and baselines prevent wasted effort in ML development?
How does the pose-estimation case study illustrate ML project planning?
What does prioritizing ML projects involve before heavy experimentation?
Review Questions
- What are the three main failure modes for AI/ML projects mentioned, and how would you detect each early?
- How do metrics and baselines work together to determine whether an ML model is truly improving?
- In the pose-estimation-to-grasp pipeline, what kinds of success criteria might differ between the pose model and the grasp model?
Key Points
- 1
Machine learning projects fail often in large companies; one cited survey reports 85% failure.
- 2
A major driver of failure is that ML still behaves like research, making outcomes less predictable than typical software engineering.
- 3
Technical infeasibility can keep systems from ever reaching production reliability.
- 4
Unclear success criteria prevent teams from knowing whether progress is real.
- 5
Poor management of ML teams adds unique friction compared with conventional software development.
- 6
Production ML work should be planned as a lifecycle with explicit activities and early feasibility/value prioritization.
- 7
Metrics and baselines are foundational: metrics define what “better” means, while baselines provide the reference for judging improvement.