4. Archetypes - ML Projects - Full Stack Deep Learning
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
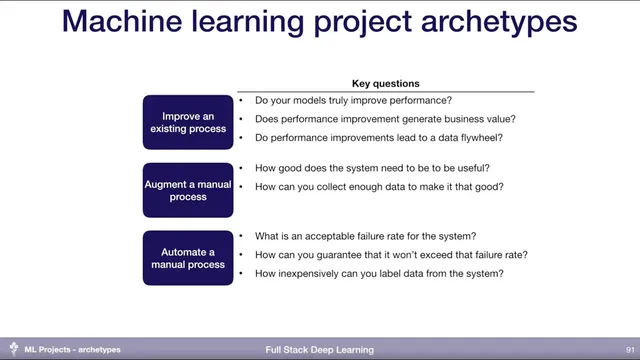
Machine learning projects cluster into three archetypes—improving, augmenting, and automating—and each archetype changes what “success” must prove.
Briefing
Machine learning projects tend to fall into three archetypes—improving an existing process, augmenting a manual workflow, or automating a manual workflow—and each archetype forces different success criteria. The biggest practical takeaway is that “better model metrics” only matter if they translate into measurable downstream outcomes and real business value; otherwise teams risk building technically impressive systems that don’t move the needle.
For projects that improve an existing process—such as upgrading IDE code completion, moving from coarse category-based recommendations to highly personalized ones, or replacing hand-tuned game AI rules with reinforcement learning—the central challenge is proving the improvement where it counts. That requires strong instrumentation and principled production deployment so teams can verify that model changes actually improve downstream metrics tied to user behavior. Even then, performance gains must map to business value: if recommendations increase clicks but the business doesn’t benefit, the work may not be worth doing. A further question is whether gains create a data flywheel: better predictions can lead to a better product, which attracts more users, which generates more (and ideally better) data for training.
For projects that augment manual processes—turning sketches into slides, offering email auto-completion, or speeding up radiology work—the bar shifts from “replace the workflow” to “make the human faster without breaking trust.” Teams need to determine how good the system must be to be genuinely useful and how to collect enough data to reach that level. The key difference from pure improvement projects is that augmentation often lacks built-in data collection, so teams must design mechanisms to gather feedback and training signals.
For projects that automate manual processes—fully automated customer support, fully automated design, or self-driving—feasibility hinges on failure rates and coverage. Even a model that achieves 99.999% accuracy on validation data may still fail more often than desired in the real world unless the dataset is comprehensive enough to represent what the system will encounter. That leads to two hard operational questions: how to guarantee real-world failure-rate targets, and how to label new data cheaply when the system makes mistakes. If predictions can’t be automatically verified, teams must rely on costly manual labeling, which can stall iteration.
The discussion then ties these archetypes to an impact-versus-feasibility trade-off. Improving existing processes is usually the most feasible but often has the lowest ceiling on impact. Impact can rise when teams build data loops that automatically collect and label user data, enabling continuous performance improvement and potentially expanding automation over time. Augmentation and automation become more feasible through product design and faster releases: shipping a “good enough” version early helps move from augmentation-from-scratch toward measurable improvement. Product design examples include Facebook’s tag suggestions that let users confirm labels, Grammarly’s suggestions that remain user-in-the-loop, and Netflix explanations that invite feedback.
When full automation is the goal, teams typically add humans in the loop or enforce guardrails that restrict operation to safer boundaries. The session also highlights alternative learning paradigms and applications beyond the classic supervised setup: DARPA’s early self-driving work used high-quality sensing (like lidar) to label cheaper sensors after the fact, reinforcement learning reframes learning as specifying success rather than providing step-by-step instructions, and large-scale, hard-to-interpret domains like fraud detection illustrate cases where humans can’t process the data but models can. Finally, generative systems—such as video generation and voice replication—show how machine learning can create capabilities that didn’t exist before.
Cornell Notes
Machine learning projects cluster into three archetypes: improving an existing process, augmenting a manual workflow, and automating a manual workflow. Each archetype demands different proof of success: improvement projects must show downstream metric gains and business value; augmentation projects must reach “good enough” quality and gather data despite limited built-in labeling; automation projects must meet strict real-world failure-rate targets and handle comprehensive coverage and costly labeling.
A central concept is the data flywheel: better models can improve the product, attract more users, and generate more data that further improves models. Feasibility often starts highest in “improve” projects, then can grow in impact through product design, early “good enough” releases, and data loops. For full automation, humans-in-the-loop and guardrails are common strategies to make safety targets achievable.
How do teams avoid the trap of “better model accuracy” that doesn’t improve what matters in production?
What’s the key difference between augmenting a manual process and improving an existing process?
Why is validation-set accuracy insufficient for fully automated systems like self-driving?
What makes labeling hard in automation projects, and how does that affect iteration speed?
How can product design increase the feasibility and impact of ML projects?
What alternative learning paradigms were cited as going beyond classic supervised learning?
Review Questions
- Which downstream metrics and business outcomes should be instrumented to prove that an “improve an existing process” ML project is actually working?
- What dataset coverage and labeling strategy would you design to ensure a target real-world failure rate for a fully automated system?
- How would you build a data flywheel for an augmentation workflow where labels aren’t naturally generated?
Key Points
- 1
Machine learning projects cluster into three archetypes—improving, augmenting, and automating—and each archetype changes what “success” must prove.
- 2
Improvement projects need production instrumentation that links model changes to downstream metrics and business value, not just offline accuracy.
- 3
Augmentation projects must define how good the system must be to help users and must engineer ways to collect enough data despite limited built-in labeling.
- 4
Automation projects require real-world failure-rate guarantees, which depend on dataset comprehensiveness and on capturing/labeling mistakes efficiently.
- 5
A data flywheel can turn model improvements into more users and more training data, but it only works if the product truly improves and data collection is automated.
- 6
Good product design and early “good enough” releases can raise feasibility by creating feedback loops and moving teams from augmentation toward measurable improvement.
- 7
Humans-in-the-loop and guardrails are common strategies to make full automation safer and more feasible.