40x Faster Binary Search
Based on The PrimeTime's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Reorganize static search data for cache-line locality; Eytzinger’s implicit heap layout can outperform binary search once arrays exceed L3 due to effective prefetching.
Briefing
High-throughput searching over a static, sorted array can beat classic binary search by reorganizing data for cache prefetching and then squeezing the remaining work through SIMD, batching, and careful memory layouts. The core target is a “static search tree” (an S+ tree variant) that returns, for each query Q, the smallest stored value ≥ Q (or u32 max when no such value exists). Instead of optimizing per-query latency, the work measures reciprocal throughput—how many independent queries can be answered per second—because modern CPUs can hide long memory waits when many queries are in flight.
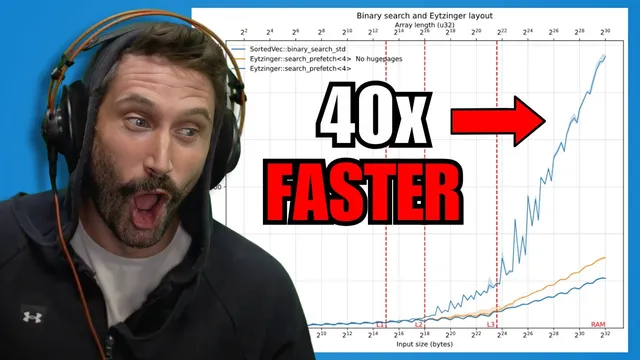
The project starts from a baseline: Rust’s standard library binary_search over a sorted Vec<u32>. It then compares against an “Eytzinger” (implicit heap) layout, which reorders the array so that the next few binary-search steps land in nearby cache lines. That locality enables hardware prefetch to pull in values for several iterations ahead, letting the CPU overlap cache misses with useful work. When the dataset fits in cache, Eytzinger looks similar to binary search; once the array grows beyond L3, it can become several times faster—roughly matching the idea that prefetching four iterations ahead hides traversal latency.
From there, the S+ tree design focuses on cache-line efficiency rather than pointer chasing. The tree is stored as contiguous 64-byte-aligned nodes (16 u32 values per node), packed so that each cache line contains enough information to advance multiple logical levels. The layout duplicates keys across internal nodes (S+ / B+ style) so searches can avoid extra comparisons while descending. A key performance lever is branchlessness: rather than stopping early when a comparison fails, the search counts how many lanes are less than the query and uses popcount to compute the first index where the value is ≥ Q. SIMD vectorization turns the “linear scan within a node” into parallel comparisons, and subsequent hand-tuned AVX2 intrinsic work reduces instruction count and fixes unsigned-compare limitations by mapping u32 values into an i32-safe range.
The biggest throughput gains come from systems-level tactics. Batching multiple queries lets the CPU issue many memory reads concurrently; prefetching the next tree node for each query further smooths stalls when data lives in L3 or RAM. Interleaving work across tree levels—processing layer i for many in-progress batches—helps balance CPU-bound early steps with memory-bound later steps, improving overall throughput even when single-thread latency is not the focus.
The transcript also tests variants: changing node branching factor (e.g., 15 vs 16 values), reversing or fully expanding layouts, and partitioning the keyspace by prefix bits into multiple smaller trees. Partitioning can help on skewed real-world inputs (like DNA k-mers from human genome data) but often adds complexity and extra lookups, and it doesn’t consistently beat the simpler interleaved batching approach. Multi-threading then pushes the system toward the real bottleneck: aggregate RAM bandwidth. With enough threads, throughput approaches near-optimal behavior, and the overall speedup relative to baseline binary search reaches roughly 40x.
The takeaway is less about one magical data structure and more about aligning algorithms with CPU realities: memory ordering, cache-line packing, SIMD-friendly branchless logic, and throughput-oriented batching can dominate asymptotic “O(log n)” expectations in practice—especially for static search workloads like suffix-array searching in bioinformatics.
Cornell Notes
Static search trees can outperform classic binary search when the goal is throughput, not single-query latency. By storing an S+ tree in contiguous, cache-line-aligned nodes and using branchless SIMD (counting comparisons with popcount), the search turns many steps into efficient parallel work. Throughput rises further when many queries are batched and interleaved across tree levels, letting the CPU overlap cache misses and hide RAM latency. Prefetching the next node for each query adds incremental gains, especially once data spills from L3 into RAM. On large inputs, multi-threading shifts the bottleneck to total RAM bandwidth, and the best layouts approach near-optimal throughput.
Why does measuring reciprocal throughput (queries per second) change what “best” means compared with latency?
What makes the Eytzinger (implicit heap) layout faster than a plain sorted array binary search on large datasets?
How does the S+ tree search stay branchless and SIMD-friendly inside each node?
Why does batching and interleaving across tree levels matter once data is in RAM?
Why does partitioning by prefix bits help on skewed real data but often underperform on uniform random inputs?
What ultimately limits throughput at scale in the multi-threaded experiments?
Review Questions
- Which combination of techniques (layout, SIMD, batching, interleaving, prefetching) most directly targets hiding cache-miss latency, and why?
- Explain how popcount-based lane counting replaces a branchy “find first ≥ Q” inside a node. What does it compute?
- Why does partitioning by prefix bits introduce overhead, and under what input distributions does that overhead become worthwhile?
Key Points
- 1
Reorganize static search data for cache-line locality; Eytzinger’s implicit heap layout can outperform binary search once arrays exceed L3 due to effective prefetching.
- 2
Shift from latency optimization to throughput optimization by using reciprocal throughput metrics and focusing on hiding memory stalls.
- 3
Store the S+ tree in contiguous, 64-byte-aligned nodes and use branchless logic inside nodes (SIMD comparisons + popcount) to compute the first index where value ≥ Q.
- 4
Use batching to keep many queries in flight and interleave work across tree levels so CPU-bound and memory-bound phases overlap efficiently.
- 5
Prefetch the next required node per query to smooth stalls; benefits are largest when data lives in L3/RAM, smaller when already in L1.
- 6
Tune SIMD implementation details to match hardware constraints (e.g., unsigned-compare limitations in AVX2) and reduce instruction count via hand-tuned intrinsics.
- 7
At high thread counts, total RAM bandwidth becomes the bottleneck; further speedups require fewer memory accesses per query, not just faster per-core code.