#7 Visualizing Branching Off in your Archive • Zettelkasten Live
Based on Zettelkasten's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Split bloated notes into linked structure nodes that preserve the argument: premises/suspiciousness, reasoning, and a compact conclusion.
Briefing
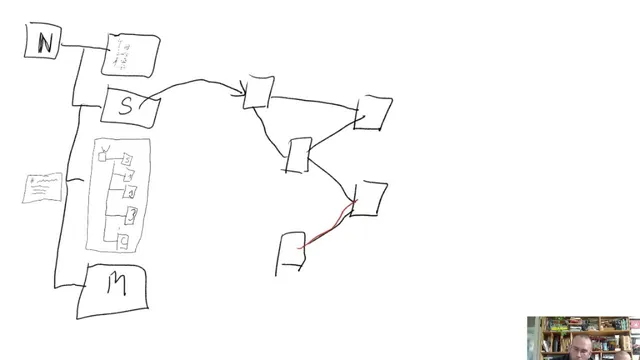
The core insight is that knowledge archives need more than tags and links—they need explicit “structure nodes” that separate reasoning from conclusions, so the archive can produce meaningful trails of thought instead of a messy cloud of text. In practice, the Telecast method’s visual workflow turns bloated notes into a network of structured components: a conclusion node, supporting “reasoning” nodes, and a “suspiciousness” or premise layer that signals what warrants further inquiry. That separation matters because it makes the archive navigable at multiple levels—by hierarchy (zooming out from specifics to general categories) and by trail (following connections backward or forward through context).
The demonstration begins with a single note about wheat—“wheat is deadly”—that quickly becomes too large to manage. The workflow then “crops out” the content and rebuilds it as linked notes: the conclusion remains as a compact claim, while the supporting parts become distinct nodes. The middle layer is treated as arguments: reasons that justify the conclusion, and a premise-like part that flags why the topic is worth investigating in the first place (e.g., whether wheat contains anti-nutrients or lacks beneficial nutrients). Headings in the example are mostly for readability; in a real archive, the structure is meant to be implicit in the node relationships rather than hard-coded as labels.
From there, the session expands into two structural modes. First is hierarchy, which emerges when structured notes are organized into a general-to-specific ladder. A broad nutrition node can link to subtopics like fasting, supplements, wheat, meat, and then drill down further (fasting → fat metabolism → muscle hypertrophy → microbiome → weight loss). Second is connected trails, which resemble storylines: a node like “supplements” can link to a specific protein-powder thread, and following links creates a path that can be argumentative or exploratory. Reading backward along links yields a “trail” of context—useful for reconstructing how an idea was built.
The most pointed critique targets tagging-only systems. A “cloud” of concepts connected only indirectly through hashtags can be searchable, but it lacks the direct, structured connections that make knowledge work productive. The example of linking “Hitler” to “emptiness” illustrates the difference: in a structured archive, an indirect trail can reveal an original association created by the researcher’s own reasoning path, even if that connection doesn’t exist in an external “platonic” world of pure ideas. That personal trail is framed as the archive’s value—exclusive access to one’s own adapted network of concepts.
Finally, the discussion argues that automation fails when it only has access to unstructured text clouds. Knowledge growth is treated as a sequence of decision-heavy steps—data to information to knowledge to wisdom—where relevance filtering and value judgments can’t be reduced to simple computation. Machines can process what’s provided, but they can’t supply the researcher’s preferences, moral judgments, or “wisdom” defined as acting appropriately on existing knowledge. The takeaway is pragmatic: build structure yourself, so the archive can support real thinking rather than just retrieval.
Cornell Notes
The Telecast method’s key move is turning bloated notes into “structure nodes” that separate conclusions from reasons and premises. By cropping content into linked components, an archive can support both hierarchy (general-to-specific zooming) and trails (following connections like storylines or argument paths). This structure makes navigation and synthesis more reliable than tagging-only systems, which often leave ideas floating in an unstructured “cloud.” The discussion also frames why automation struggles: knowledge work depends on decision points—especially relevance and judgment—that can’t be inferred from raw text alone. The result is an archive that preserves the researcher’s own reasoning trail, enabling original connections.
How does a “structure node” change a note that has grown too big?
What two structural patterns emerge in a well-built archive?
Why does tagging-only search fall short for knowledge work?
What does the “Hitler” to “emptiness” example illustrate?
Why is automation described as limited in this framework?
How does the archive support writing projects like books or articles?
Review Questions
- When converting a bloated note into a structure node, which parts become separate linked nodes, and what role does each part play in the argument?
- How do hierarchy and trails differ in how a reader navigates an archive, and what kinds of thinking does each support?
- What decision-heavy steps in the data→information→knowledge→wisdom ladder are described as difficult for automation to replicate?
Key Points
- 1
Split bloated notes into linked structure nodes that preserve the argument: premises/suspiciousness, reasoning, and a compact conclusion.
- 2
Use hierarchy to organize general-to-specific topics so zooming out reveals the overall map of a domain.
- 3
Use trails to follow connections like storylines, enabling both exploratory reading and systematic argument reconstruction.
- 4
Treat tagging-only “clouds” as insufficient because they often lack direct, reasoning-based links needed for synthesis.
- 5
Build structured direct links so the archive can generate original associations through the researcher’s own trail of thought.
- 6
Expect automation to struggle when knowledge work depends on relevance filtering and value judgments rather than text retrieval alone.
- 7
Use the same structure logic to support writing: start from structured components (concepts, evidence, conclusion) and let linked nodes expand the draft coherently.