Abstract Linear Algebra 34 | Eigenvalues and Eigenvectors for Linear Maps
Based on The Bright Side of Mathematics's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
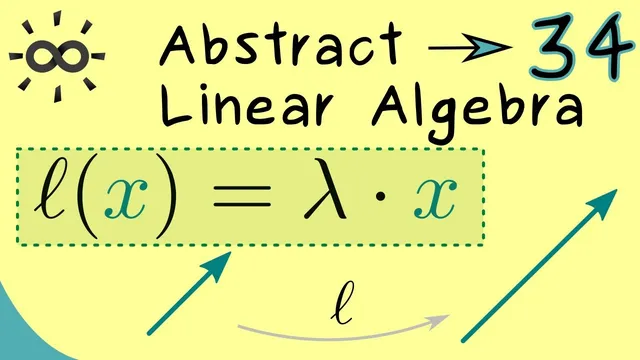
A nonzero vector X is an eigenvector of L if L(X) lies in the span of X, equivalently L(X)=λX for some scalar λ.
Briefing
Eigenvectors and eigenvalues for a linear map are defined by a simple “scaling” condition: a nonzero vector X is an eigenvector of L if L(X) lands in the same direction as X, meaning L(X)=λX for some scalar λ. This matters because it turns a potentially complicated linear transformation into something predictable on the eigenvector directions—just multiplication by λ—so the structure of L becomes easier to analyze.
The definition works in both finite and infinite-dimensional vector spaces, without requiring any matrix representation. The only restriction is that an eigenvector cannot be the zero vector: since L(0)=0, the zero vector would satisfy the scaling condition trivially and would not carry meaningful information. For any nonzero X, the corresponding scalar λ is the eigenvalue associated with that eigenvector. Importantly, λ can be any element of the underlying field F, including 0.
A key reformulation links eigenvalues to kernels. Starting from L(X)=λX and rearranging gives (L−λI)(X)=0, where I is the identity map. That means λ is an eigenvalue exactly when the linear map L−λI has a nontrivial kernel (i.e., contains vectors other than 0). The set of all eigenvectors for a fixed eigenvalue λ is precisely the kernel of L−λI, excluding the zero vector; this kernel is called the eigenspace. Since kernels are subspaces, each eigenspace forms a subspace of V (and adding 0 keeps it a subspace).
In finite dimensions, the same eigenvalue condition can be checked using matrices. If a basis is chosen, L−λI corresponds to a matrix, and the dimension of the kernel is preserved under passing to that matrix representation. As a result, eigenvalues do not change when moving between the abstract linear map and its matrix form. Practically, this lets eigenvalues be computed by the familiar matrix method: solve the characteristic polynomial obtained from det(A−λI). The transcript emphasizes that the determinant-based approach is not just a computational trick—it matches the abstract kernel criterion.
The motivation for developing the abstract viewpoint comes from infinite-dimensional settings. A concrete example uses the vector space C^1 of real-valued functions on the real line whose derivative is continuous. On this space, differentiation is a linear map L(f)=f′. Eigenvectors arise naturally: the exponential function e^x is its own derivative, so L(e^x)=e^x, meaning e^x is an eigenvector with eigenvalue 1. This example shows that eigenvalues and eigenvectors extend beyond finite-dimensional linear algebra, even though fully characterizing them in infinite-dimensional spaces becomes more subtle—often requiring tools from functional analysis.
Overall, the core insight is that eigenvalues are exactly the scalars λ for which L−λI fails to be injective (has a nontrivial kernel), and eigenvectors are the nonzero vectors in that kernel. That single idea unifies the abstract definition, the matrix characteristic-polynomial method, and infinite-dimensional examples like differentiation on function spaces.
Cornell Notes
Eigenvectors and eigenvalues of a linear map L are defined by the scaling rule L(X)=λX for some scalar λ and some nonzero vector X. Equivalently, λ is an eigenvalue exactly when (L−λI)(X)=0 has nontrivial solutions, meaning the kernel of L−λI is not just {0}. The eigenspace for λ is the kernel of L−λI (including 0), and it is a subspace of V. In finite-dimensional spaces, passing to a matrix representation preserves the kernel condition, so eigenvalues can be computed via the characteristic polynomial det(A−λI). In infinite-dimensional spaces, the same abstract definition still applies; for instance, differentiation on C^1 has e^x as an eigenvector with eigenvalue 1.
Why must an eigenvector be nonzero in the definition?
How does the equation L(X)=λX turn into a kernel condition?
What exactly is an eigenspace, and what vectors does it contain?
Why do eigenvalues computed from matrices match the abstract definition?
How does the differentiation example produce an eigenvalue and eigenvector?
Review Questions
- State the definition of an eigenvector and eigenvalue for a linear map L on a vector space V.
- Prove (or explain) why λ is an eigenvalue of L iff ker(L−λI) is nontrivial.
- In finite dimensions, how does the characteristic polynomial det(A−λI) relate to the kernel condition for eigenvalues?
Key Points
- 1
A nonzero vector X is an eigenvector of L if L(X) lies in the span of X, equivalently L(X)=λX for some scalar λ.
- 2
Eigenvalues can be any element of the field F, including 0; the definition imposes no extra restriction on λ.
- 3
λ is an eigenvalue exactly when the kernel of L−λI contains vectors other than 0.
- 4
For each eigenvalue λ, the eigenspace is ker(L−λI), forming a subspace of V whose nonzero elements are the eigenvectors.
- 5
In finite-dimensional settings, eigenvalues are unchanged when moving between an abstract linear map and its matrix representation.
- 6
Matrix computation of eigenvalues via det(A−λI)=0 matches the abstract kernel criterion.
- 7
Infinite-dimensional examples still fit the same framework: differentiation on C^1 has e^x as an eigenvector with eigenvalue 1.