Advanced RAG with Llama 3 in Langchain | Chat with PDF using Free Embeddings, Reranker & LlamaParse
Based on Venelin Valkov's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Use LlamaParse to convert complex, table-heavy PDFs into structured markdown before any embedding or retrieval happens.
Briefing
Building a high-quality “chat with your PDF” system hinges less on the language model and more on the pipeline around it: parsing complex documents into clean text, chunking and embedding that text, retrieving the most relevant chunks, reranking them, and only then prompting the LLM with tightly scoped context. The workflow demonstrated here uses open models and LangChain to create an advanced RAG stack that can answer questions about a complex financial PDF (Meta’s first-quarter earnings results) with improved retrieval ordering via a dedicated reranker.
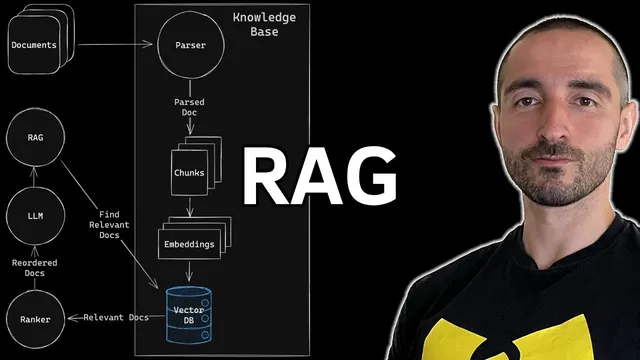
The architecture is organized into three main components: a knowledge base, a ranker, and a chat language model (W 3 accessed through the Gro API). The knowledge base starts by parsing the PDF into structured, readable markdown. For this, the setup uses LlamaParse, chosen specifically for messy, table-heavy financial documents where formatting and nested structures (tables within tables, bullets, intricate layouts) often break simpler parsers. After parsing, the markdown is split into overlapping text chunks using a recursive character splitter (2,048 characters per chunk with 128 characters of overlap). Each chunk is then embedded into vectors using FastEmbed embeddings, and those vectors are stored in a local Qdrant vector database.
Retrieval happens in two stages. First, Qdrant performs similarity search against the user’s query to fetch the top candidates (the example uses top-k retrieval of five). This stage returns documents with similarity scores, but the retrieved ordering isn’t always optimal for downstream answering. To fix that, the system adds a reranker using Flashrank (via the Flashrank wrapper around the base retriever). The reranker performs pairwise ranking to filter out irrelevant chunks and reorder the most relevant ones at the top. In the example run, reranking adds noticeable latency (around a few seconds), but it also produces a more useful set of context documents for the LLM.
Finally, the reranked documents and the user question are combined into a prompt for the LLM (Llama 3 70B). The prompt is designed to use the provided context and reduce hallucinations—explicitly instructing the model to answer only when helpful information is present and to avoid inventing details. The chain is implemented as a LangChain question-answering flow with a “stuff” strategy, meaning the retrieved context is inserted into the prompt as a single block.
The system’s behavior is tested with concrete questions about Meta’s earnings PDF. It correctly identifies items like the “most significant innovation” (tied to the new version of Meta AI with W 3 mentioned in a Zuckerberg quote), and it extracts numeric values from tables such as 2024 revenue (36,455 million) and 2023 revenue (28,645 million), including percentage year-over-year change. It also handles arithmetic questions derived from the tables, though not perfectly: one revenue-minus-cost calculation for 2023 is shown to be wrong, illustrating that even with strong retrieval and reranking, the LLM can still make mistakes when performing multi-step computations.
Overall, the build demonstrates that advanced RAG quality comes from disciplined document-to-vector preparation and retrieval refinement (parser + chunking + embeddings + Qdrant + reranker), while the LLM’s prompt can only partially mitigate errors—especially for calculations—without additional safeguards.
Cornell Notes
The pipeline for “chat with a PDF” is built around three parts: a knowledge base that turns PDFs into chunked embeddings, a reranker that improves which chunks reach the LLM, and an LLM (Llama 3 70B via Gro API) that answers using the retrieved context. The knowledge base uses LlamaParse to convert a complex, table-heavy financial PDF into structured markdown, then splits it into overlapping chunks (2,048 chars with 128 overlap), embeds them with FastEmbed, and stores vectors in Qdrant. Retrieval starts with Qdrant similarity search (top-k candidates), then Flashrank reranks those candidates using pairwise ranking to push the most relevant chunks to the top. In tests on Meta earnings content, the system extracts table values accurately and answers quote-based questions well, but it can still make arithmetic mistakes, showing that retrieval quality doesn’t fully eliminate LLM errors.
Why does the build emphasize LlamaParse for financial PDFs instead of relying on generic PDF text extraction?
How do chunking choices affect retrieval quality in this RAG setup?
What role does Qdrant play, and what does “top five” retrieval mean here?
What does the reranker change compared with raw vector similarity search?
How does the prompt design try to reduce hallucinations, and what limitation remains?
What does the “stuff” chain type imply for how context is fed to the model?
Review Questions
- If the parser produced poorly formatted markdown from a table-heavy PDF, which downstream steps would likely degrade first: chunking, embeddings, retrieval, or reranking—and why?
- In this setup, where does the system spend most of its time: embeddings, vector search, reranking, or LLM inference? Identify the approximate timings mentioned and what each stage accomplishes.
- Why can a RAG system answer quote-based questions well yet still fail on arithmetic derived from extracted table values?
Key Points
- 1
Use LlamaParse to convert complex, table-heavy PDFs into structured markdown before any embedding or retrieval happens.
- 2
Split parsed markdown into overlapping chunks (2,048 characters with 128 overlap) to preserve context across boundaries.
- 3
Store chunk embeddings in Qdrant and start retrieval with similarity search (e.g., top-k candidates) to narrow the search space.
- 4
Add a reranker (Flashrank) after vector retrieval to reorder and filter candidates using pairwise ranking for better context quality.
- 5
Feed the reranked context plus the user question into Llama 3 70B via Gro API using prompt instructions that discourage hallucinations.
- 6
Expect remaining failure modes for multi-step computations even when retrieval and reranking are strong; consider adding validation or calculator-style checks if accuracy is critical.