All in One (8) - Infrastructure and Tooling - Full Stack Deep Learning
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
All-in-one deep learning platforms aim to unify compute provisioning, experiment tracking, model versioning, deployment, and production monitoring in a single workflow.
Briefing
The push toward “all-in-one” deep learning infrastructure is about replacing a patchwork of point tools with a single system that can take models from notebook-based development through training and deployment—then keep watching them in production. The payoff is operational simplicity: one place to provision compute (CPU or GPU), track experiments, version models, deploy trained models, and monitor real-world performance. That end-to-end workflow matters because teams otherwise spend time stitching together incompatible tools, duplicating effort, and paying hidden coordination costs.
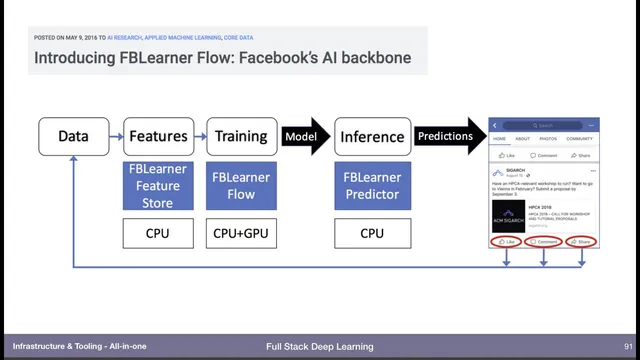
Early momentum for this unified approach came from major industry platforms. Facebook’s FB1/Flow described an AI platform spanning data to features, training on GPUs, deployment on CPUs, and monitoring predictions—plus feedback loops back into the data source. Google’s Michelangelo and the later TensorFlow ecosystem followed a similar production-scale arc, with tooling for ingesting and transforming data, training at scale, and serving models on Google Cloud. Amazon’s SageMaker also targets the same lifecycle, promising managed data collection and labeling, scalable training, managed environments, one-click deployment, and monitoring.
SageMaker’s tradeoff is price. The transcript highlights a roughly 40% markup versus running equivalent workloads directly on EC2—for example, a K80 instance costing $1 on AWS might cost $1.40 when provisioned through SageMaker. The justification is convenience: notebooks start with the right GPU/CUDA configuration, experiments get tracked automatically, and the platform handles operational details.
A wave of startups built similar “unified workflow” systems, often with more flexibility across clouds and hardware. Neptune ML Lab emphasizes collaboration and experiment comparison while running on local or cloud resources. FloydHub, PaperSpace, and Gradient describe workflows that move from development to training to measurement to deployment. Determined AI starts on-prem but also supports cloud, adding features like hyperparameter tuning using Hyperband (linked to a founder’s Hyperband paper) and distributed training wrappers.
The most feature-rich option singled out is Domino Data Lab. It supports selecting compute types (CPU, GPU, and managed notebook environments), tracking experiments, and deploying trained models as REST APIs with one click. It also includes monitoring that compares prediction distribution charts against training-data distribution, flagging when production behavior diverges. Domino further offers lightweight “applets” (Streamlit-style) to share model outputs via a URL, plus spend monitoring so teams can see instance usage, who launched what, and project-level notes and metrics.
Despite the abundance of platforms, there’s no universal “correct” choice. The practical recommendation is to understand the whole stack—hardware provisioning, experiment management, hyperparameter optimization, model storage/versioning, deployment, and monitoring—so teams can decide whether a fully managed platform fits their constraints. If a team already has strong AWS alignment or lacks DevOps support, SageMaker may be sensible despite the markup. If the team can manage Kubernetes and wants cost control, building infrastructure themselves could be preferable. What practitioners should avoid is reinventing core components: experiment tracking, model management, and similar systems are better handled by existing tools, whether that means combining point solutions or adopting a true all-in-one platform.
Cornell Notes
All-in-one deep learning platforms aim to unify the full lifecycle: provision CPU/GPU compute, run notebooks and experiments, track results and model versions, deploy models (often as REST APIs), and monitor production behavior. Major ecosystems such as Facebook’s Flow, Google’s Michelangelo/TensorFlow, and AWS SageMaker established the pattern, but each comes with tradeoffs—especially SageMaker’s reported ~40% markup over equivalent EC2 usage. Startups like Neptune, FloydHub, PaperSpace, Gradient, Determined AI, and Domino Data Lab extend the same lifecycle with varying strengths, including Domino’s prediction-vs-training distribution monitoring and cost/spend dashboards. The key takeaway is that no single platform wins for everyone; teams should understand the stack and choose based on cloud constraints, DevOps capacity, and desired operational convenience.
Why do teams seek “all-in-one” infrastructure instead of stitching together point tools?
What lifecycle elements do major platforms (and startups) typically unify?
What is the practical tradeoff highlighted for AWS SageMaker?
How does Domino Data Lab’s monitoring differ from basic “is it working?” dashboards?
Why is there no single “clearly correct” platform recommendation?
What should practitioners avoid doing even if they have engineering resources?
Review Questions
- Which parts of the deep learning lifecycle are most likely to break when teams rely on separate point solutions, and how does an all-in-one platform address them?
- Under what circumstances might a team accept SageMaker’s reported ~40% markup, and when might that cost push them toward self-managed infrastructure?
- What monitoring signals (beyond accuracy) does Domino Data Lab provide to detect issues in production, and why does comparing prediction vs training distributions matter?
Key Points
- 1
All-in-one deep learning platforms aim to unify compute provisioning, experiment tracking, model versioning, deployment, and production monitoring in a single workflow.
- 2
SageMaker’s convenience comes with a reported ~40% cost markup over equivalent EC2 instances, such as $1 vs $1.40 for a K80 example.
- 3
The main decision hinges on constraints: cloud commitment (e.g., AWS-only), availability of DevOps expertise, and tolerance for managed-platform pricing.
- 4
Startups offer similar lifecycle coverage with different strengths, including collaboration, distributed training, hyperparameter tuning, and flexible cloud/hardware options.
- 5
Domino Data Lab stands out for features like one-click REST API deployment, prediction-vs-training distribution monitoring, and cost/spend visibility by team and project.
- 6
No universal “best” platform exists; practitioners should understand the full stack to make an informed choice.
- 7
Rebuilding core components like experiment management is generally unnecessary because specialized providers already cover those functions.