Attention in transformers, step-by-step | Deep Learning Chapter 6
Based on 3Blue1Brown's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Attention updates token embeddings by computing query-key relevance scores, normalizing them with softmax, and using the resulting attention pattern to weight value vectors.
Briefing
Attention in transformers is the mechanism that lets each token’s embedding absorb information from other tokens—turning context-free word vectors into context-rich representations that can accurately predict the next word. The core move is to compute, for every token position, a set of relevance scores against every other position, normalize those scores with a softmax, and then use them as weights for a weighted sum of “value” vectors. That weighted sum becomes the update to the token’s embedding, so meanings shift depending on surrounding words rather than staying stuck to a lookup-table identity.
The process starts with embeddings: each token maps to a high-dimensional vector that encodes both the token’s identity and its position. While the initial embedding for a word like “mole” is the same across different sentences, attention later determines which other tokens should influence it. In the examples, “mole” changes meaning across “American shrew mole,” “one mole of carbon dioxide,” and “take a biopsy of the mole,” because the attention mechanism routes information from the surrounding context into the “mole” embedding. A similar idea appears with “tower”: when preceded by “Eiffel,” the model can steer the representation toward the Eiffel Tower; when preceded by “miniature,” it can shift away from large, tall associations.
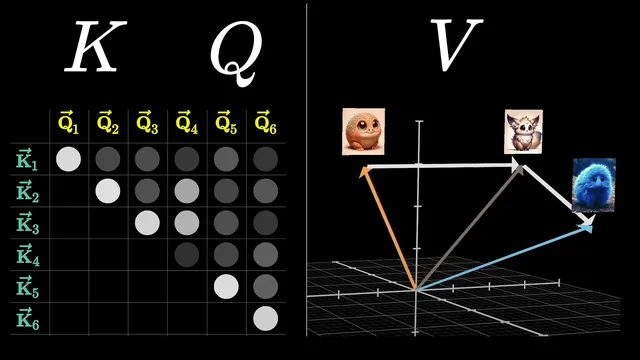
To compute these context-dependent updates, a single attention head builds three learned linear projections of the embeddings: queries (Q), keys (K), and values (V). Each token produces a query vector and a key vector in a smaller “query-key space” (for GPT-3, 128-dimensional), using learned matrices wq and wk. Relevance is measured by dot products between every query and every key, producing a grid of scores. Those scores are scaled by the square root of the key-query dimension for numerical stability, then normalized with a softmax (applied column-by-column) to form an attention pattern—effectively a set of probability-like weights indicating which source tokens matter for updating each target token.
Training adds an important constraint: masking prevents later tokens from influencing earlier ones. During next-token prediction, allowing future context to leak backward would make the task artificially easy, so entries corresponding to “future-to-past” influence are set to negative infinity before softmax, forcing their weights to become zero while keeping normalization intact.
Once the attention pattern is computed, the head updates embeddings using the value vectors. A learned value matrix maps each token embedding into a high-dimensional value vector; each token’s embedding update is a weighted sum of these value vectors, where weights come from the attention pattern. Conceptually, “fluffy” and “blue” contribute strongly to the update of “creature” in the phrase “a fluffy blue creature roamed the verdant forest,” shifting the noun embedding toward a more specific meaning.
Multi-headed attention runs many such heads in parallel, each with its own Q/K/V projections, so the model can learn multiple distinct context-update strategies at once. GPT-3 uses 96 attention heads per block, and the parameter count per block is enormous—around 600 million for multi-headed attention alone. Across 96 layers, attention parameters total just under 58 billion, about a third of the roughly 175 billion parameters in GPT-3, with the rest largely residing in the feed-forward (MLP) components between attention blocks.
Finally, attention’s success isn’t only about what it computes; it’s also about how efficiently it scales. The operations are highly parallelizable on GPUs, aligning with the broader deep-learning lesson that scale and throughput often translate into better performance. The result is a mechanism that turns context into actionable routing: tokens selectively pull meaning from other tokens, repeatedly, across layers, until high-level abstractions can emerge.
Cornell Notes
Attention in transformers updates each token’s embedding by letting it selectively “pull” information from other tokens. A single attention head computes queries, keys, and values from token embeddings, then scores relevance using dot products between queries and keys. Softmax turns those scores into an attention pattern, and masking prevents future tokens from influencing earlier ones during next-token prediction. The head then forms a weighted sum of value vectors to produce the embedding update. Multi-headed attention repeats this in parallel with many different learned projections (GPT-3 uses 96 heads), enabling multiple context-update strategies at once and supporting large-scale, GPU-parallel training.
Why can the same token embedding represent different meanings of a word like “mole” across sentences?
How do queries, keys, and dot products translate into “which words matter to which other words”?
What does masking do, and why is it necessary for next-token prediction?
How does the attention pattern actually change embeddings?
Why does multi-headed attention help compared with a single head?
What is the practical bottleneck of attention, and why do people seek variants?
Review Questions
- In what exact step does a token’s meaning become context-dependent, and what computation produces the weights used for that update?
- Why does masking require setting scores to negative infinity before softmax rather than simply forcing them to zero?
- How do the dimensions of the query/key space and the scaling by the square root affect the attention score computation?
Key Points
- 1
Attention updates token embeddings by computing query-key relevance scores, normalizing them with softmax, and using the resulting attention pattern to weight value vectors.
- 2
Initial embeddings encode token identity and position but not surrounding context; context enters through attention-driven weighted sums of other tokens’ value vectors.
- 3
Queries and keys come from learned linear projections of embeddings into a smaller space (e.g., 128 dimensions in GPT-3), and relevance is measured with dot products.
- 4
Softmax normalization turns raw dot-product scores into an attention pattern, which acts like a distribution of how much each token should influence another.
- 5
Masking prevents future tokens from influencing earlier ones during next-token training by forcing disallowed attention weights to zero after softmax.
- 6
Multi-headed attention runs many attention heads in parallel (GPT-3 uses 96), sums their proposed embedding updates per position, and increases the model’s capacity for different context-update strategies.
- 7
Attention is computationally heavy because its pattern scales with the square of context length, but it remains attractive because it parallelizes efficiently on GPUs.