Binomial distributions | Probabilities of probabilities, part 1
Based on 3Blue1Brown's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Treat each seller’s quality as an unknown success rate S, with each review an independent positive/negative draw.
Briefing
Online ratings tempt buyers to treat “% positive” as a direct measure of quality, but the number of reviews changes what that percentage really means. A seller with 100% positives from 10 reviews can be less trustworthy than a seller with 96% from 50 reviews, because small samples make extreme outcomes far more likely. The central task is turning that intuition into a rational rule: how to trade off the confidence gained from more data against the fact that the observed percentage might be inflated or deflated by chance.
A simple rule of thumb is introduced first: pretend there were two additional reviews—one positive and one negative—so a rating of 10/10 becomes 11/12 (91.7%). For 48/50 positives, the adjusted estimate becomes 49/52 (94.2%), and for 187/200 it becomes 187+? leading to 187/202 (92.6%). Under this “rule of succession,” the second seller (96% with 50 reviews) comes out best, even though the first seller’s displayed rating is higher.
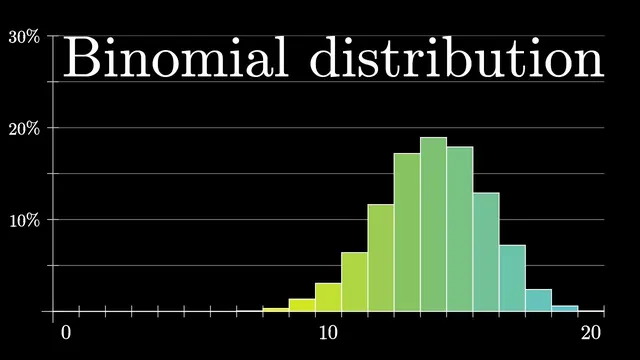
To justify such behavior quantitatively, the discussion sets up a probabilistic model. Each seller has an unknown underlying success rate S: the probability any given experience is positive. Reviews are treated as independent draws from this success rate. The observed counts—say 48 positive and 2 negative out of 50—are then modeled as outcomes of a binomial process. If S were known, the probability of seeing exactly those counts would follow the binomial distribution: “(50 choose 48) times S^48 times (1−S)^2.” This formula matters because it tells how plausible different values of S are given the data.
The binomial distribution is then examined from two angles. First, for a fixed S (like 0.95), simulations show that getting an extreme result such as 10 out of 10 positives is not rare—around 60% of the time in the example—so the data alone doesn’t prove the seller is truly perfect. Second, for fixed data (like 48 out of 50), the binomial probability as a function of S peaks near the observed proportion (around 0.96) but falls off quickly as S moves away. With more data, the curve becomes narrower and more concentrated, reflecting increased confidence.
A key tension is highlighted: the binomial curve’s peak corresponds to the most likely S, but that does not automatically translate into a personal probability of having a good experience. For 10/10 positives, the likelihood keeps increasing as S approaches 1, yet no buyer should conclude a 100% guarantee. The missing step is converting “probability of the data given S” into “probability of S given the data,” which requires Bayes’ rule. That transition is deferred to the next part, where Bayesian updating and continuous probability distributions are brought in.
Cornell Notes
The ratings problem is modeled by assuming each seller has an unknown success rate S: the probability a single experience is positive. Given a fixed S, the number of positive reviews out of N follows a binomial distribution, with probability proportional to (N choose k)·S^k·(1−S)^(N−k). This lets buyers quantify how likely different S values are after observing counts like 48 positives and 2 negatives. But the binomial likelihood’s peak (the most likely S) is not the same as the buyer’s probability of a good experience, especially when small samples make extreme outcomes plausible. Converting from “P(data|S)” to “P(S|data)” requires Bayes’ rule, which comes next.
Why can a 100% rating from 10 reviews be less convincing than a 96% rating from 50 reviews?
If the true success rate S were known, how do you compute the probability of seeing 48 positive and 2 negative reviews out of 50?
What does the binomial curve look like when you fix the data and vary S?
Why doesn’t the peak of the binomial likelihood automatically give the buyer’s probability of a good experience?
What mathematical step is needed to turn “P(data|S)” into “P(S|data)”?
How does Laplace’s rule of succession relate to the “add two imaginary reviews” idea?
Review Questions
- Given observed counts k positives out of N, write the binomial likelihood in terms of S and explain what each factor represents.
- Explain why increasing the number of reviews makes the binomial likelihood curve narrower even if the observed proportion stays the same.
- In the 10/10 example, why is it unreasonable to treat the likelihood peak near S=1 as a literal 100% probability of future success?
Key Points
- 1
Treat each seller’s quality as an unknown success rate S, with each review an independent positive/negative draw.
- 2
Use the binomial distribution to compute P(data|S) for observed counts like 48 positives and 2 negatives out of 50.
- 3
Small samples make extreme outcomes plausible: even with S=0.95, 10/10 positives can occur frequently.
- 4
For fixed data, the binomial likelihood as a function of S peaks near the observed proportion but falls off sharply away from it.
- 5
More data concentrates the likelihood around the observed proportion, increasing confidence about S.
- 6
The decision requires converting P(data|S) into P(S|data), which is done with Bayes’ rule rather than reading off the likelihood peak.
- 7
Laplace’s rule of succession corresponds to adding one positive and one negative pseudo-count, yielding conservative adjusted success-rate estimates.