Biology of LLMs - Part 1
Based on West Coast Machine Learning's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Transformer interpretability is harder than CNN interpretability because attention/MLP interactions and stacked nonlinearities obscure a clean feature hierarchy.
Briefing
Mechanistic interpretability is moving from “what concepts are stored where” toward “how those concepts get used to produce the next token.” The session lays out the background for Anthropic’s “Biology of LLMs” work—especially its focus on Claude 3.5 Haiku and a smaller, unnamed transformer—and explains why understanding modern transformer behavior is harder than earlier circuit work on CNNs.
The talk traces interpretability’s evolution. Early “distill circuits” research treated neural nets like electrical circuits: break models into smaller units, study individual components, and map how signals flow. That approach worked well for CNNs, where lower layers reliably detect simple features (edges, lines) and higher layers compose them into more complex ones (textures, shapes, even faces). Transformers, however, introduce far more nonlinearities and a tangled interaction between attention and MLP blocks. The session highlights a key obstacle: transformers stack dozens of layers, and each layer’s internal representations shift as information moves through attention heads and feed-forward networks.
A central theme in the preceding wave of transformer-circuit research is “superposition.” Instead of dedicating one direction in representation space to one concept, LLMs can pack many concepts into a limited-dimensional residual stream. When concepts are not orthogonal and appear together, they interfere—sometimes canceling out in dot-product probes. Earlier papers used compressed-sensing-style arguments and experiments to show that this interference can be tolerated when concepts are sparse in the training distribution: if two concepts rarely co-occur, the model can reuse directions without catastrophic collisions. The session uses a toy example in a 2D space to illustrate how increasing sparsity changes the geometry from clean orthogonal “compass directions” to a “pentagon” arrangement where multiple concepts coexist with controlled interference.
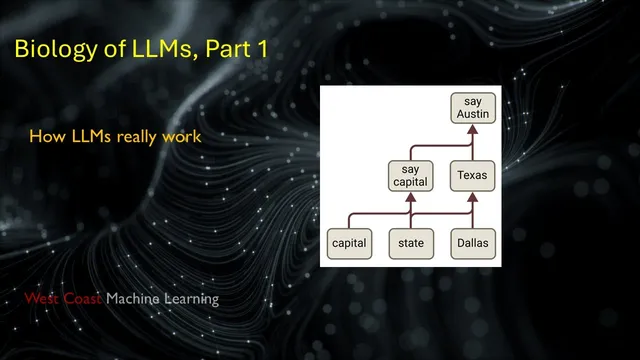
But knowing that concepts exist as directions (and that they can be recovered) still doesn’t answer the practical question: how do those directions drive generation? The session frames Anthropic’s next step as studying the MLPs—because attention mainly moves information across token positions, while MLPs operate on the current token’s residual stream. Attention can “pull” earlier facts into the present position, enabling the MLP to act on them; without that pull, MLPs can’t directly access earlier tokens. The residual stream itself is treated as the shared workspace: if attention and MLP outputs were zeroed, the model would fall back to a default next-token prediction, implying that meaningful information already lives in the stream and layers add, subtract, or nudge it.
The background also emphasizes how attention is analyzed in circuit frameworks: Q and K determine attention patterns (a probability distribution over prior token positions), while the values and output projections affect which subspaces get written to the residual stream. That separation matters because later interpretability work can focus on attention patterns without needing the raw Q/K magnitudes.
Finally, the session explains why Anthropic’s “biology” approach is different from earlier direction-finding work using sparse autoencoders. Prior work could recover millions of concept directions, but diagnosing how they get used across layers remained out of reach. The promised technique replaces the original model with progressively simpler surrogate models: first a sparsified replacement model, then a “local replacement model” tailored to a specific prompt. By hardcoding attention patterns and removing nonlinearities, the relationship between layers becomes linear enough to compute influence on the next token directly. The approach then validates hypotheses back on the original model, aiming to connect recovered concepts to concrete causal effects inside specific MLP layers—moving interpretability from geometry to mechanism.
Cornell Notes
The session builds the groundwork for Anthropic’s “Biology of LLMs,” arguing that interpretability must go beyond finding concept directions and instead show how those directions causally drive next-token generation. Earlier transformer work established “superposition”: many concepts share a limited-dimensional residual stream, and interference depends on whether concepts co-occur. Attention primarily moves information across token positions, while MLPs act on the current token’s residual stream; thus, attention can enable MLPs by pulling earlier facts forward. Sparse autoencoders and compressed-sensing ideas can recover millions of concept directions, but they don’t reveal how those concepts are used inside later layers. The promised solution uses prompt-specific “local replacement models” that simplify the network enough to compute layer-by-layer influence, then tests those hypotheses on the original model.
Why is transformer interpretability harder than earlier CNN “circuit” work?
What does “superposition” mean in LLM representations, and why does sparsity matter?
How do attention and MLP layers differ in what they can “see”?
What is the residual stream, and why does it matter for interpretability?
How do circuit frameworks treat attention components (Q, K, V, and output projections)?
What problem remains after recovering concept directions with sparse autoencoders?
Review Questions
- How does concept co-occurrence affect interference in superposition, and what role does sparsity play in making dot-product decoding feasible?
- Why can attention enable MLPs to use earlier-token facts, while MLPs alone cannot access earlier positions?
- What does a “local replacement model” aim to simplify, and how does linearization make layer-by-layer influence easier to compute?
Key Points
- 1
Transformer interpretability is harder than CNN interpretability because attention/MLP interactions and stacked nonlinearities obscure a clean feature hierarchy.
- 2
Superposition packs many concepts into a limited-dimensional residual stream; interference depends on whether concepts co-occur in the same context.
- 3
Attention primarily moves information across token positions, while MLPs operate on the current token’s residual stream and rely on attention to pull earlier facts forward.
- 4
The residual stream functions as the shared workspace where layers add, subtract, and nudge concept directions that ultimately drive next-token prediction.
- 5
Sparse autoencoders and compressed-sensing-style methods can recover concept directions, but they don’t automatically reveal how those concepts are causally used across layers.
- 6
Anthropic’s “biology” approach targets mechanism by using prompt-specific local replacement models that simplify away nonlinearities and hardcode attention patterns to enable linear influence calculations.
- 7
Validation returns to the original model to test whether hypotheses derived from simplified surrogates hold under the full nonlinear transformer dynamics.