Bombshell Paper Shows AI Has Thinking Collapse. Or Does It?
Based on Sabine Hossenfelder's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
A study using odd-one-out image classification found large models can form object representations that behave like human concepts, and those representations align with neural activity patterns in object-related brain regions.
Briefing
A pair of near-simultaneous research papers is forcing a rethink of what “AI reasoning” really means: one line of work finds striking human-like object representations and brain alignment, while another reports a sharp accuracy breakdown in more complex reasoning tasks—followed by a rebuttal that blames output limits rather than cognition. The practical takeaway is that today’s large models may show fragments of human-like thinking, but they don’t yet display the broad, generalizable intelligence people often assume.
One lesser-known study examined how large language models and vision-capable counterparts classify images. Researchers repeatedly presented both humans and the models with sets of three images and asked them to pick the odd one out. By varying these comparisons, they built a quantitative measure of “similarity” among images. The results suggested the models develop “human-like conceptual representations of objects.” Even more consequential, the team compared internal activation patterns from the model networks with neural activity in the brain and reported “strong alignment” between model embeddings and neural activity in brain regions tied to object understanding. The authors interpret this as evidence that, while model representations aren’t identical to human ones, they share fundamental similarities reflecting core aspects of human conceptual knowledge.
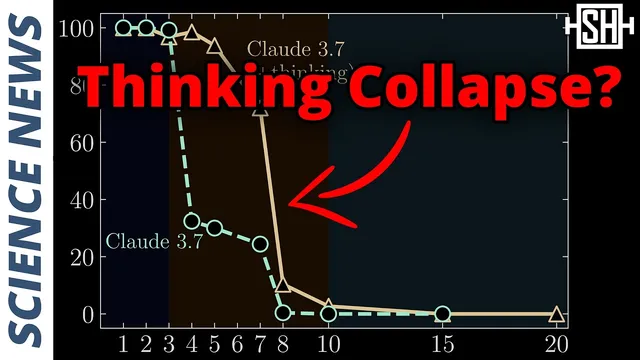
The headline-grabbing Apple paper took a different angle: it focused on large reasoning models—large language models augmented with chain-of-thought prompting and training. These systems break prompts into smaller steps, solve subproblems, analyze intermediate results, and then recombine them. The Apple team tested performance on deterministic logic puzzles with algorithmic solutions that the models could, in principle, use. Their central claim was that accuracy collapses at a “frontier” as puzzle complexity increases, implying a limit in how far the models can carry out the kind of stepwise reasoning the setup demands.
Within days, a follow-up paper challenged that conclusion. It argued the apparent collapse wasn’t a failure of reasoning ability itself, but a constraint tied to how many tokens the model can output—effectively the maximum length of the generated chain-of-thought. Preliminary tests were presented in support of this alternative explanation.
The broader debate, as framed here, isn’t just about which paper is right; it’s about definitions. Image classification and algorithm execution are narrow proxies for “thinking” and “reasoning” as humans experience them. Even so, the evidence points to a limited form of cognition: current systems can reason a little and execute algorithms, but the capability doesn’t generalize in the way people expect from human-like intelligence. Instead of acquiring hallmarks such as deductive and inductive analysis, abstract theorizing, rapid learning, and robust generalization, the models appear to scale by handling more tasks with more training and compute—without necessarily developing the deeper cognitive machinery associated with intelligence.
The implication is sobering for anyone expecting imminent AGI. If “reasoning” is measured by general, theory-building intelligence, today’s models may not be on that trajectory. And as these systems become embedded in everyday internet workflows—coding, browsing, and interacting with users—the safety implications of increasingly capable but still limited reasoning could arrive before the field fully agrees on what the models can truly do.
Cornell Notes
Two research threads pull in opposite directions on whether current AI “thinks.” One study uses odd-one-out image classification and finds human-like object representations in large models, plus strong alignment between model embeddings and neural activity in brain regions related to object concepts. Another study on Apple’s chain-of-thought reasoning models reports a sharp accuracy collapse as deterministic logic puzzles become more complex. A follow-up paper argues the collapse is driven by token-output limits (maximum chain length) rather than a fundamental reasoning failure. Together, the results suggest today’s systems can mirror parts of human conceptual processing but lack the general, theory-building intelligence people often expect.
What evidence suggests large models develop human-like object concepts?
How do “large reasoning models” differ from standard large language models in these studies?
What did the Apple paper claim happens as puzzle complexity increases?
Why did a follow-up paper dispute the “reasoning collapse” interpretation?
What is the key critique of using these benchmarks to define “thinking” or “reasoning”?
Review Questions
- Which experimental design elements (odd-one-out trials, similarity construction, neural alignment) support the claim of human-like conceptual representations in models?
- What two competing explanations are offered for the reported accuracy collapse in complex reasoning puzzles?
- Why does the transcript argue that algorithm execution and classification are insufficient proxies for general human reasoning?
Key Points
- 1
A study using odd-one-out image classification found large models can form object representations that behave like human concepts, and those representations align with neural activity patterns in object-related brain regions.
- 2
Apple’s chain-of-thought reasoning models were tested on deterministic, algorithmic puzzles, with results reported as a sharp accuracy collapse beyond a complexity threshold.
- 3
A follow-up paper challenged that conclusion by attributing the collapse to token-output limits that cap the length of generated chain-of-thought traces.
- 4
The debate turns on definitions: classification and algorithm execution are narrow proxies for the broader, generalizable reasoning associated with human intelligence.
- 5
Current models appear to scale task coverage with more training and compute, but they don’t clearly acquire the deeper cognitive hallmarks—abstract theory-building, rapid learning, and robust generalization.
- 6
Expectations of imminent AGI may be overstated if “reasoning” is measured by general intelligence rather than benchmark performance under constraints.