But what is a neural network? | Deep learning chapter 1
Based on 3Blue1Brown's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
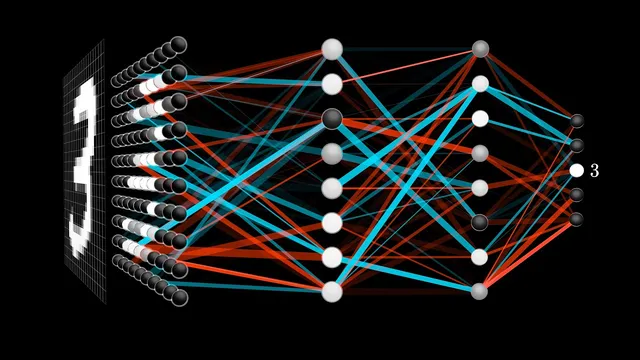
A simple digit-recognition neural network maps 784 pixel inputs to 10 digit scores using two hidden layers of 16 neurons each.
Briefing
Handwritten-digit recognition becomes feasible once a neural network is treated as a layered math machine: each “neuron” computes a weighted sum of earlier activations, adds a bias, then passes the result through a squashing function. In the simplest setup, a 28×28 grayscale image (784 pixel values) feeds a network with 16 neurons in each of two hidden layers and 10 output neurons—one per digit—so the network’s final decision is simply the output neuron with the highest activation. The striking part is that the same architecture can generalize across wildly different pixel patterns that humans still read as the same digit.
The structure starts with an input layer of 784 neurons, each holding a number between 0 and 1 representing a pixel’s brightness. Hidden layers then transform those numbers into new activations, and the output layer converts the final hidden representation into 10 activations interpreted as “how much the system thinks” the image matches each digit. The middle layers are where abstraction is expected to emerge: a digit like 9 might be decomposed into subcomponents such as loops and line segments, with earlier neurons responding to simpler features (like edges) and later neurons responding to combinations (like the loop-plus-line configuration that distinguishes 9 from 8 or 4). Even if the exact internal features aren’t guaranteed, the layered design provides a plausible path from raw pixels to meaningful parts.
To make that transformation concrete, each neuron in a hidden layer is connected to every neuron in the previous layer. Every connection has a weight, and each neuron also has a bias. The neuron computes a weighted sum of the previous layer’s activations; weights act like learned “dials” that emphasize certain pixel regions or patterns and suppress others. For instance, if a neuron’s weights are mostly positive in a region and negative around it, the weighted sum becomes large when the image contains a contrast pattern consistent with an edge. Because the raw weighted sum can be any real number, the network applies a nonlinearity to map it into a usable range. In this classic introductory version, that nonlinearity is the sigmoid (logistic) function, which pushes very negative inputs toward 0 and positive inputs toward 1, with a smooth transition around 0. The bias shifts the threshold at which the neuron begins to activate meaningfully.
With two hidden layers of 16 neurons each, the model contains roughly 13,000 trainable parameters (weights and biases). “Learning” means finding a setting for these parameters that makes the network output the correct digit for many examples—an alternative to manually engineering edge detectors and digit-combiners by hand. Mathematically, the layer-to-layer computation is compactly expressed using matrix-vector products: activations form vectors, weights form matrices, biases form vectors, and the sigmoid is applied component-wise. This structure turns a complicated overall mapping—from 784 inputs to 10 outputs—into repeated, efficient linear algebra operations.
A final reality check comes from a discussion with Lisha Li: while sigmoid was historically used to model neuron activation, modern deep networks often favor ReLU (rectified linear unit) because it trains more easily. ReLU outputs zero for negative inputs and passes positive inputs through unchanged, and it has become the go-to choice for enabling very deep architectures to learn effectively.
Cornell Notes
The core idea is that a neural network is a layered function that converts pixel values into digit scores. Each neuron computes a weighted sum of activations from the previous layer, adds a bias, and then applies a nonlinearity (in this intro version, sigmoid) to produce an activation between 0 and 1. For handwritten digits, a 28×28 image becomes 784 inputs, which feed two hidden layers of 16 neurons, ending in 10 output neurons whose largest activation indicates the predicted digit. The layered design is motivated by the hope that early layers capture simple features like edges, while later layers combine them into digit-specific patterns. Learning is the process of adjusting about 13,000 weights and biases so the network outputs the correct digit from data.
Why does the architecture use layers instead of trying to map pixels directly to digits?
What exactly does a single neuron compute in this model?
How do weights and biases relate to detecting patterns like edges?
What does “learning” mean in this context?
How is the layer-to-layer computation written more compactly?
Why does the discussion shift from sigmoid to ReLU?
Review Questions
- In the 28×28 digit model, how many input neurons and output neurons are used, and what do their activations represent?
- Describe the role of weights versus biases in a neuron’s computation, including how sigmoid changes the output range.
- Explain how matrix-vector multiplication corresponds to moving activations from one layer to the next.
Key Points
- 1
A simple digit-recognition neural network maps 784 pixel inputs to 10 digit scores using two hidden layers of 16 neurons each.
- 2
Each neuron computes a weighted sum of previous activations, adds a bias, then applies a nonlinearity to produce an activation between 0 and 1 (sigmoid in this intro).
- 3
Layering is motivated by the expectation that early layers can capture simpler features (like edges) while later layers combine them into digit-level patterns.
- 4
Weights act like learned pattern detectors by emphasizing some input regions and suppressing others; biases shift the activation threshold.
- 5
The model’s capacity comes from roughly 13,000 trainable parameters (weights and biases) that must be tuned during learning.
- 6
Layer transitions can be expressed compactly as matrix-vector products plus bias vectors, followed by element-wise nonlinearities.
- 7
Modern practice often replaces sigmoid with ReLU because ReLU is easier to train and supports very deep networks.