Complete Transformers For NLP Deep Learning One Shot With Handwritten Notes
Based on Krish Naik's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Transformers replace RNN-based recurrence with self-attention to enable parallel token processing and better scalability on large datasets.
Briefing
Transformers replaced RNN-based sequence models by solving two long-standing bottlenecks: training scalability and context-aware word representations. Earlier encoder–decoder systems compressed an entire input sentence into a single “context vector,” which broke down as sentence length grew, hurting translation accuracy. Attention improved that by letting the decoder consult different parts of the source sentence via alignment scores and attention weights, but the architecture still relied on recurrent processing that forced tokens through time steps—making parallel training difficult and limiting scalability on large datasets.
Transformers keep the encoder–decoder idea for sequence-to-sequence tasks like machine translation, but swap recurrence for self-attention. Self-attention sends all token embeddings through the model in parallel, enabling efficient training on huge corpora. It also produces contextual embeddings: instead of mapping a word to a fixed vector (e.g., “crush” always having the same representation), the model recomputes a token’s representation using relationships to other tokens in the sentence. That contextual dependency is presented as the reason Transformers handle long-range meaning better and support transfer learning for modern generative AI.
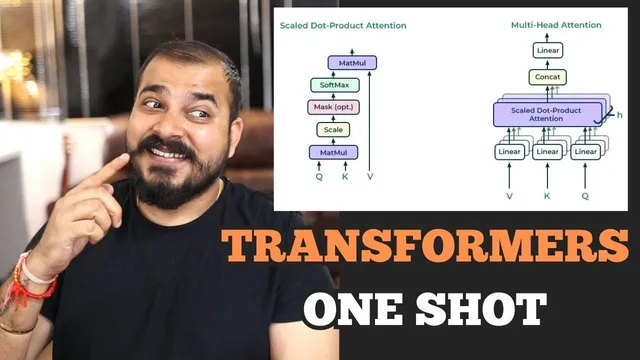
The core self-attention mechanism is built from Query, Key, and Value projections (Q, K, V). Each token embedding is linearly transformed using learned weight matrices into Q, K, and V vectors. Attention scores come from scaled dot products between queries and keys, then a softmax converts those scores into attention weights. The “scaled” part—dividing by √d_k—is emphasized as crucial for stable training: without scaling, dot products can become large, softmax can saturate (making gradients tiny/unstable), and training can suffer from gradient explosion or vanishing-gradient-like behavior. After softmax, the attention weights are used to compute a weighted sum of the value vectors, producing contextual vectors.
To broaden what the model can attend to at once, Transformers use multi-head attention. Multiple attention heads run in parallel with different learned Q/K/V projections, capturing different dependency patterns (for example, one head might focus on syntactic links while another captures semantic relationships). The outputs of heads are concatenated and projected back into a single representation before passing onward.
Because self-attention processes tokens in parallel, it needs help with word order. Positional encoding injects sequence position information into token embeddings. The transcript highlights sinusoidal positional encoding, where sine and cosine functions of different frequencies generate bounded values (between −1 and 1), avoiding unbounded growth that would occur if positions were simply appended as raw indices. These positional vectors are added to embeddings so the model can distinguish “lion eats tiger” from “tiger kills lion.”
Inside each Transformer block, residual connections (“add”) and layer normalization (“normalize”) stabilize learning. Residuals provide shortcut paths that help gradients flow through deep stacks, while layer normalization standardizes activations per layer to reduce internal covariate shift.
The encoder architecture stacks multiple identical layers (the transcript references six encoders and six decoders from the original design). Each encoder layer contains self-attention, multi-head attention, residual + layer normalization, and a feed-forward neural network that adds nonlinearity and enriches token-wise representations.
The decoder mirrors the encoder but adds masked multi-head self-attention to enforce autoregressive generation. Two masking types are described: padding masks prevent attention to padded tokens, and look-ahead masks prevent attending to future tokens. The transcript explains how combined masks set disallowed attention scores to −∞ so softmax assigns them zero probability.
Finally, the decoder’s output vectors are mapped to vocabulary logits via a linear layer, then converted into probabilities with softmax. Training uses the known target sequence (shifted right with start tokens and padding), computes loss between predicted and target tokens, and updates all learned weights through backpropagation. The result is a complete pipeline from token embeddings and attention math to probability-based word generation for sequence-to-sequence NLP.
Cornell Notes
Transformers solve encoder–decoder weaknesses by replacing recurrence with self-attention, enabling parallel training and producing contextual embeddings. Self-attention builds Query, Key, and Value vectors from token embeddings, computes scaled dot-product attention scores, applies softmax to get attention weights, then forms contextual vectors as a weighted sum of values. Multi-head attention runs several attention heads in parallel to capture different dependency patterns, and positional encoding injects word order information so parallel processing doesn’t lose sequence order. Residual connections and layer normalization stabilize deep stacks, while the decoder uses masking (padding + look-ahead) to prevent attention to future tokens during autoregressive generation. A final linear layer plus softmax turns decoder outputs into vocabulary probabilities for each time step.
Why did encoder–decoder models struggle with long sentences, and how did attention change that?
What exactly makes self-attention “contextual,” and how do Q, K, V produce that effect?
Why is the attention score scaled by √d_k, and what training problems does it prevent?
How does multi-head attention differ from single-head attention in what it learns?
What problem does positional encoding solve, and why does the transcript emphasize sinusoidal encoding?
Why does the decoder use masking, and how do padding masks and look-ahead masks work together?
Review Questions
- In self-attention, what is the exact sequence of operations from embeddings to contextual vectors (Q/K/V, attention scores, scaling, softmax, weighted sum)?
- How do padding masks and look-ahead masks differ in purpose, and what would go wrong in translation if either mask were removed?
- Why do residual connections and layer normalization matter when stacking multiple encoder/decoder layers?
Key Points
- 1
Transformers replace RNN-based recurrence with self-attention to enable parallel token processing and better scalability on large datasets.
- 2
Self-attention produces contextual embeddings by computing attention weights from Query–Key similarity and using those weights to aggregate Value vectors.
- 3
Scaled dot-product attention (divide by √d_k) stabilizes training by preventing softmax saturation and keeping gradients well-behaved.
- 4
Multi-head attention improves representation quality by letting different heads learn different dependency patterns via separate learned Q/K/V projections.
- 5
Positional encoding is required because parallel self-attention alone loses word order; sinusoidal encoding injects bounded position signals.
- 6
Decoder masking enforces correct sequence generation: padding masks ignore padded tokens, and look-ahead masks prevent attending to future tokens.
- 7
A linear layer maps decoder outputs to vocabulary logits, and softmax converts logits into per-token probabilities for the next word.