Context Engineering is the future of AI Agents - here’s why
Based on David Ondrej's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
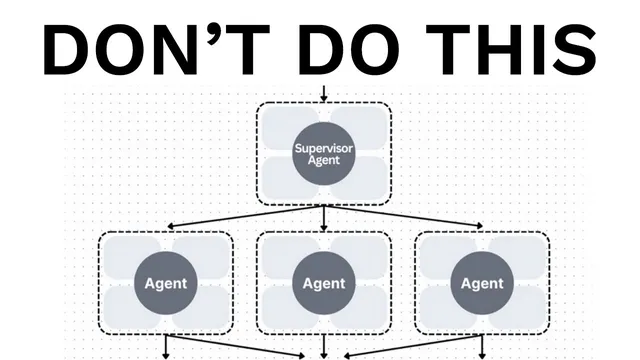
Multi-agent “teams” are often less reliable than expected because parallel sub-agents make decisions under incomplete shared context.
Briefing
Multi-agent “teams” are a reliability trap for most production AI agents, and the fix is simpler: design around context sharing and make action sequences explicit. The central claim is that splitting work across multiple agents—especially in parallel—creates inconsistent assumptions and compounding errors, so systems that look impressive in demos often fail once they run for real users and real tasks.
The argument draws on an article from Cognition AI (co-founded by Walden, tied to the Devon agent) that warns against the growing hype around frameworks that encourage multi-agent architectures, including OpenAI Swarm and Microsoft Autogen. Even when examples are “simple,” they still push developers toward multiple agents for tasks that don’t need them. The reliability problem shows up quickly: the more complexity added—more agents, more coordination steps, more moving parts—the lower the system’s dependability.
Two principles sit at the core of the critique. First, “share context” not just as short user/assistant messages, but as full agent traces—what each agent saw, how it reasoned, and what it produced. Second, “actions carry implicit decisions.” When different agents make conflicting decisions without a shared, synchronized understanding, the final merger step becomes fragile. The transcript illustrates this with a common pattern: a manager agent breaks a task into subtasks, parallel sub-agents generate partial outputs, and a final agent tries to combine them. In a design example, one sub-agent assumes a vibrant futuristic setting while another assumes dark gritty tones; the combiner is left to reconcile incompatible creative directions. In a Flappy Bird-style example, one agent may build green pipes and hitboxes while another builds a bird with movement and visuals that don’t match the environment, producing a “complete mess” because the agents never truly align.
The proposed alternative is a single-threaded, linear architecture that preserves decision continuity. A manager agent still decomposes tasks, but sub-agents run sequentially: the second sub-agent receives the full context plus the first sub-agent’s outputs before acting. This prevents the “parallel inconsistency” failure mode. A code walkthrough demonstrates the difference: instead of async parallel execution, the system awaits the first sub-agent, then calls the second with updated context, and only then merges results.
That linear approach isn’t perfect for very long workflows. Context windows can overflow as the conversation and action history grows. For longer-duration tasks, the transcript recommends adding context compression: a dedicated compressor summarizes conversation and actions in real time so downstream agents operate on a condensed but decision-relevant record. The caveat is that compression adds complexity and is hard to get right—something even major labs struggle with—so the advice is to use compression only when tasks truly require it.
Finally, the transcript argues against “agent collaboration” via back-and-forth negotiation. Agents aren’t humans; they lack the reliable, high-signal communication needed for consensus-building across long contexts. The practical takeaway is to keep architectures simple, ensure every action is grounded in shared, decision-relevant context, and avoid parallel multi-agent designs unless there’s a clear, engineered reason to do so.
Cornell Notes
The transcript argues that multi-agent “teams” often fail in production because parallel work leads to inconsistent assumptions and compounding errors. Two principles drive the critique: share full, decision-relevant context (including agent traces) and treat actions as carrying implicit decisions—conflicts between agents produce bad outcomes. For reliability, it recommends a single-threaded linear architecture where sub-agents run sequentially and each receives the previous agent’s outputs before acting. For very long tasks, it suggests context compression: a side process summarizes conversation and actions so later steps don’t hit context-window limits. The overall message: keep agent systems simple and context-grounded, and add complexity only when it’s necessary.
Why does parallel multi-agent work become unreliable in production?
What does “share context” mean beyond passing a prompt to each agent?
How do “actions carry implicit decisions” and “conflicting decisions” connect to system failures?
What architecture is presented as the most reliable default, and how does it work?
When does the transcript recommend adding context compression, and what problem does it solve?
Why does the transcript discourage “agents negotiating like humans” to reach consensus?
Review Questions
- In a parallel multi-agent workflow, what specific missing information prevents sub-agents from staying aligned, and how does that show up in the examples?
- Describe the step-by-step difference between the unreliable parallel design and the reliable linear design.
- What trade-off does context compression introduce, and how does it change the failure mode for long-running tasks?
Key Points
- 1
Multi-agent “teams” are often less reliable than expected because parallel sub-agents make decisions under incomplete shared context.
- 2
Two core rules guide better agent design: share full, decision-relevant context (agent traces) and recognize that every action embeds implicit assumptions.
- 3
When agents act on conflicting assumptions, the final merge step becomes fragile and produces inconsistent outputs.
- 4
A single-threaded linear architecture is the most reliable default: run sub-agents sequentially so each one sees prior outputs before acting.
- 5
For long-duration tasks, context windows can overflow; context compression can summarize conversation and actions to keep later steps grounded.
- 6
Adding compression or other advanced mechanisms increases engineering complexity; use it only when tasks truly require it.
- 7
Consensus-style agent collaboration is discouraged because agents lack the reliable communication needed for human-like negotiation across long contexts.