CrowdStrike Destroyed The Internet
Based on The PrimeTime's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
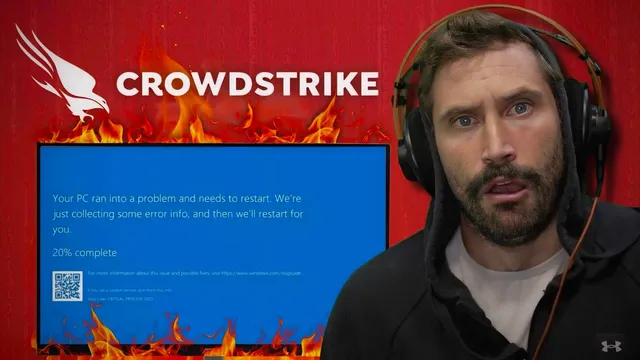
CrowdStrike’s endpoint agent uses a kernel driver, so update failures can cause immediate Windows crashes and widespread service disruption.
Briefing
A flawed CrowdStrike update triggered widespread Windows crashes by bricking endpoints through a kernel-level component, leading to cascading outages across banks, healthcare, retail, and airlines. The immediate result was “blue screen of death” failures on systems that pulled the problematic update, effectively taking critical services offline and forcing organizations into slow, hands-on recovery.
The outage’s root cause is tied to CrowdStrike’s endpoint security agent, which relies on a kernel driver to gain deep visibility and control for malware detection and prevention. Kernel drivers operate at a privileged level, so even a small mistake in the driver or its update can cause systems to fail catastrophically. During the incident, CrowdStrike referenced a “dodgy channel file” (described as a kernel-space mechanism used for internal communication between components). When the update containing the faulty element reached endpoints, those machines fell over into boot-loop or crash states, preventing normal operation.
Because the update was pushed broadly and affected systems immediately, recovery became a logistical problem rather than a purely technical one. Many affected organizations reportedly had to intervene directly on each machine—entering safe mode or using Windows recovery tools to remove or correct the problematic change. Attempts to automate fixes through tools like Group Policy were limited by the fact that machines stuck in a boot loop may not be able to receive or apply remote configuration changes reliably. In scenarios involving BitLocker, recovery also depends on having the correct per-device recovery keys, adding another layer of manual work.
The scale of the disruption is reflected in how far beyond IT departments the fallout spread: flight operations were grounded or disrupted, airport check-in and departure systems were impacted, and medical practices reported restricted online requests due to core management systems being affected. Retail and payment-related workflows also suffered because dependencies like credit card processing and inventory systems rely on stable Windows endpoints and supporting infrastructure.
A key operational lesson raised in the discussion is that security vendors need the ability to update safely—ideally with staged rollouts, canary testing, and rapid rollback strategies. Once a kernel-level update bricks systems, simply stopping further deployment may not help, because already-updated endpoints remain stuck until repaired. That makes “test and prod” discipline and gradual rollout mechanisms especially important for high-privilege components.
The conversation also broadened into why kernel-level access is used at all: deeper hooks into OS behavior can improve detection of malicious activity, but that same power increases fragility and risk. Finally, the discussion touched on supply-chain and open-source concerns—security tooling can include third-party libraries even when vendors try to minimize attack surface by building more in-house—highlighting that even mature security products can fail when low-level changes go wrong.
Cornell Notes
The CrowdStrike outage is described as a kernel-level failure: a problematic update (including a “channel file” element) caused Windows endpoints to crash into blue screen/boot-loop states. Because the endpoint agent uses a privileged kernel driver for deep security visibility, a small update mistake can have outsized impact, disrupting banking, healthcare, retail, and airline operations. Recovery often required manual intervention on affected machines—entering safe mode and applying fixes locally—rather than relying on remote management. The incident also underscores why staged rollouts, canary testing, and rollback planning matter most for high-privilege security software. Once systems are bricked, stopping further updates doesn’t automatically restore service; repair becomes a fleet-wide operations problem.
What mechanism ties CrowdStrike’s update to Windows crashes?
Why did the outage spread so quickly across critical industries?
Why was recovery so manual, and why didn’t remote fixes fully solve it?
What operational safeguards are expected for security updates at this privilege level?
Why do vendors use kernel drivers despite the fragility risk?
How do open-source and supply-chain risks fit into incidents like this?
Review Questions
- What makes kernel-driver updates uniquely dangerous compared with user-space software updates?
- Why can staged rollouts and canary testing be especially important for endpoint security agents?
- Explain how BitLocker and boot-loop states can turn a software fix into a manual recovery operation.
Key Points
- 1
CrowdStrike’s endpoint agent uses a kernel driver, so update failures can cause immediate Windows crashes and widespread service disruption.
- 2
A problematic update element described as a “channel file” is linked to endpoints falling into blue screen/boot-loop states.
- 3
Recovery often required local, hands-on repair steps like safe mode and Windows recovery tools, not just stopping the update rollout.
- 4
Remote management approaches (including Group Policy) can fail when endpoints can’t reach a stable state to receive or apply changes.
- 5
BitLocker can make recovery more labor-intensive because each device may require its own recovery key to access repair options.
- 6
High-privilege security software needs staged deployment, canary testing, and rollback planning because stopping further deployment doesn’t fix already-bricked systems.
- 7
Even security vendors that aim to reduce risk may still rely on third-party or open-source components, keeping supply-chain management relevant.