Deep Learning Frameworks
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
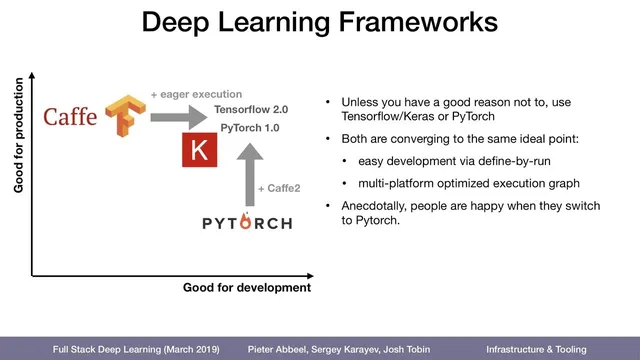
Framework choice can be mapped to two axes: developer ease and production scalability.
Briefing
Deep learning frameworks can be judged along two practical axes: how pleasant they are for building models and how well they scale once those models must run reliably in production. Early frameworks often traded one for the other—C++-heavy systems were harder to develop but excelled in speed and deployment, while newer, Python-first tools made experimentation easier at some cost to production ergonomics.
Caffe sits near the “harder to develop, strong in production” corner. It requires writing both the forward and backward passes in C++, meaning developers must derive and implement gradients themselves. That extra math work makes iteration slower, but the payoff is performance: Caffe’s C++ implementation and optimization have kept it in use for real-time and regulated domains. Financial services and other latency-sensitive applications still rely on Caffe today.
TensorFlow emerged a few years later with a different bet: make production deployment easier across commodity hardware and specialized deep-learning servers. It grew from a smaller research effort into a large Google-backed project, and it emphasized scalability and portability—running on servers, mobile devices, and more. The development experience, however, is less direct because TensorFlow uses a computational graph abstraction: code is compiled into an executable graph rather than run line-by-line. That design makes debugging harder, since typical tools like breakpoints don’t map cleanly onto the user-written model code.
Keras and later “Max 9” (as referenced in the transcript) pushed the development side forward by acting as higher-level wrappers. Keras is positioned as a friendlier interface on top of TensorFlow, while still benefiting from TensorFlow’s underlying execution once models are compiled into graphs. The tradeoff is that the wrapper can constrain what developers can express compared with writing directly in lower-level frameworks.
PyTorch, associated with Facebook researchers and built on ideas from the earlier Torch ecosystem, targets the “easy to develop” end by letting developers write in Python and execute in a way that supports interactive debugging. That makes it especially attractive for research workflows involving loops, dynamic control flow, and unconventional architectures. The transcript also highlights PyTorch’s automatic differentiation as a key reason it feels efficient for gradient-based training.
The production gap is narrowing. TensorFlow has moved toward eager execution (noted as “TensorFlow 2.0” in the transcript), while PyTorch has improved its deployment story by compiling models into optimized graphs executed via Caffe2, a C++-based component intended to run across platforms, including phones. The practical recommendation offered is to default to TensorFlow with Keras as the front end or to use PyTorch unless there’s a clear reason to choose otherwise.
Finally, adoption trends reinforce the tradeoffs: TensorFlow and Keras appear most common in job postings and practitioner usage, while PyTorch is growing quickly. Caffe remains present in “boring” but demanding industries—oil, finance, and medical—where performance and established pipelines matter more than developer convenience.
Cornell Notes
Deep learning frameworks can be evaluated on two axes: developer experience and production scalability. Caffe is difficult to develop because it requires implementing both forward and backward passes in C++, but it performs well in production and still appears in finance and other real-time industries. TensorFlow improves production deployment and portability, yet its computational-graph abstraction can make debugging harder. Keras boosts development comfort by providing a higher-level interface on top of TensorFlow, while PyTorch emphasizes easy Python-based development with interactive debugging and automatic differentiation. Both ecosystems are converging: TensorFlow’s eager execution and PyTorch’s compilation to optimized graphs via Caffe2 aim to deliver both fast iteration and practical deployment.
Why does Caffe land in the “harder to develop, strong in production” category?
What tradeoff does TensorFlow make to improve production deployment?
How do Keras and PyTorch differ in development experience?
What does “convergence” mean in the framework landscape described here?
Why does the transcript recommend TensorFlow+Keras or PyTorch by default?
What adoption signals are mentioned, and what do they imply?
Review Questions
- How does requiring manual backward-pass implementation in Caffe affect both development workflow and production performance?
- What specific mechanism in TensorFlow makes debugging less straightforward, and how does eager execution change that?
- In what way does PyTorch’s use of Caffe2 help bridge the gap between research-friendly Python development and production deployment?
Key Points
- 1
Framework choice can be mapped to two axes: developer ease and production scalability.
- 2
Caffe’s C++ design makes development harder because backward passes must be implemented manually, but it delivers strong production performance.
- 3
TensorFlow prioritizes production deployment and portability by compiling models into computational graphs, which can complicate debugging.
- 4
Keras improves development ergonomics by wrapping TensorFlow while still compiling models into TensorFlow graphs for execution.
- 5
PyTorch emphasizes Python-first development with interactive debugging and automatic differentiation, making experimentation faster.
- 6
Both TensorFlow and PyTorch are moving toward a shared ideal by improving eager execution and by compiling for optimized production execution via Caffe2.
- 7
Adoption trends point to TensorFlow/Keras as most common, with PyTorch gaining momentum and Caffe persisting in performance-critical industries.