DeepSeek Multihead Latent Attention
Based on West Coast Machine Learning's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
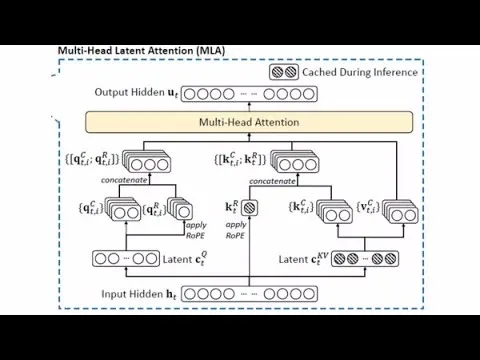
DeepSeek V2’s Multi-Head Latent Attention (MLA) reduces KV-cache memory by projecting keys/values into a lower-dimensional latent space and caching the compressed form.
Briefing
DeepSeek V2’s standout inference optimization is Multi-Head Latent Attention (MLA), a transformer attention redesign that slashes the size of the KV cache—by roughly 15×—and turns that memory win into major speedups. The practical bottleneck during long-context generation isn’t recomputing attention from scratch; it’s repeatedly loading cached keys and values from GPU memory into fast on-chip memory. By compressing what gets cached, MLA reduces the data movement cost, enabling faster token generation—reported as about 5.7× (roughly six times) compared with a “vanilla” large language model.
The core idea is straightforward but engineered carefully: instead of caching full-size key/value vectors, MLA projects keys (and values) into a lower-dimensional “latent” space, stores those compressed representations in the KV cache, and then reconstructs the full vectors only when needed for the attention dot-products and softmax. The compression is achieved through learned linear projections—for example, shrinking a 512-length key/value representation down to something like 128 or even smaller—while preserving enough information to avoid a large quality drop. DeepSeek reports that the compressed keys/values are only about 7% of the length of the full vectors, and that the model can reconstruct the originals with additional matrix multiplications.
A key reason this works is that attention’s key/value information appears to live in a relatively low intrinsic dimensional subspace. In high-dimensional spaces, many vectors behave almost orthogonally, which would normally make attention scores less selective. MLA’s success suggests that, after the per-head projections, the effective query/key space can be compressed substantially (the discussion emphasizes that selectivity depends on the geometry of the projected space, not just the raw embedding dimension). That also explains why simply reducing the key dimension “from the start” isn’t obviously equivalent: the learned projections and the geometry they create matter for matching behavior.
MLA also has to coexist with positional encoding, particularly RoPE (rotary positional embeddings). RoPE rotates queries and keys based on token distance, but caching rotated full keys would inflate the cache and complicate reuse. DeepSeek’s approach keeps the cached latent content separate from the positional component by concatenating a smaller positional/rotation-related portion so the model can recover relative-position information without storing the full rotated vectors in the cache.
Compared with earlier KV-cache reduction tactics—like Multi-Query Attention (fewer key/value heads) or Grouped-Query Attention—MLA targets a different lever. Prior methods reduce the number of cached keys/values by sharing them across heads, which often hurts benchmark performance. MLA instead keeps the number of cached items but makes each one much smaller, and it’s reported to outperform full multi-head attention on most benchmarks (with one exception). The talk also notes that MLA’s extra reconstruction compute can be mitigated by fusing adjacent matrix multiplications, so the speed gain isn’t purely “free” memory savings; it’s memory savings plus careful operator fusion.
Finally, the optimization matters because it’s tied to real deployment economics: long-context inference is expensive at scale, and cutting KV-cache load time by ~6× directly reduces GPU pressure. The discussion frames MLA as an inference-first architectural innovation introduced in DeepSeek V2 and largely retained in later variants, with the main payoff coming during generation rather than training.
Cornell Notes
DeepSeek V2’s Multi-Head Latent Attention (MLA) makes long-context inference faster by compressing what gets stored in the KV cache. Instead of caching full-size keys and values, MLA projects them into a lower-dimensional latent space, stores the compressed representations, and reconstructs full keys/values only when computing attention. This reduces KV-cache memory load—an inference bottleneck—by about 15×, translating to roughly 5.7× faster token generation. MLA also adapts RoPE by separating positional/rotation information from the cached latent content, so relative-position behavior is preserved without caching full rotated keys. Benchmarks reported in the discussion suggest MLA can match or even beat full multi-head attention quality while delivering large speedups.
Why does KV-cache size matter so much during long-context generation?
How does MLA reduce KV-cache memory without reducing the number of attention heads’ cached items?
What makes compressing keys/values plausible without destroying attention selectivity?
Why is RoPE a special challenge for KV-cache compression, and how does MLA handle it?
How is MLA different from Multi-Query Attention and Grouped-Query Attention?
What prevents MLA from losing speed due to extra reconstruction compute?
Review Questions
- What part of long-context inference becomes the main bottleneck as context length increases, and how does MLA target it?
- Explain the difference between reducing the number of cached key/value heads (multi-query/grouped-query) versus compressing each cached key/value vector (MLA).
- How does positional encoding (RoPE) complicate KV-cache compression, and what does MLA do to keep relative-position behavior while storing less?
Key Points
- 1
DeepSeek V2’s Multi-Head Latent Attention (MLA) reduces KV-cache memory by projecting keys/values into a lower-dimensional latent space and caching the compressed form.
- 2
Inference speed improves because KV-cache loading from GPU memory into fast compute memory is the dominant bottleneck for long contexts, not recomputing attention from scratch.
- 3
MLA reconstructs full-size keys/values only when needed for attention dot products and softmax, using learned projections.
- 4
RoPE is handled by separating positional/rotation information from the cached latent content (via concatenation), avoiding the need to cache full rotated keys.
- 5
Compared with Multi-Query Attention and Grouped-Query Attention, MLA compresses cached vectors rather than sharing fewer key/value heads, which helps preserve benchmark performance.
- 6
Reported results indicate MLA can match or outperform full multi-head attention on most benchmarks while delivering about 5.7× faster token generation.
- 7
Operator fusion can reduce reconstruction overhead, so the speed gain is not purely from smaller cache loads.