Diffusion Policy Controlling Robots - Part 1
Based on West Coast Machine Learning's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Diffusion policy treats robot control as a conditional denoising diffusion process that generates short action sequences rather than single-step actions.
Briefing
Diffusion policy is being positioned as a practical way to teach robots dexterous, vision-guided manipulation from relatively few demonstrations—often hours of learning after teleoperated data collection—while handling “either-or” (multimodal) action choices more reliably than several common imitation-learning baselines. The core idea is to treat robot control as a conditional denoising diffusion problem: given observations (state or images), the system generates a whole sequence of future actions by iteratively refining a noisy action trajectory toward high-probability behaviors learned from data.
A Toyota Research Institute announcement frames the motivation around real-world contact-rich tasks where robots struggle without touch feedback—pancake flipping is highlighted as a case where success improves once the robot can sense interaction with the surface. The same message emphasizes speed and scale: a small set of teleoperated skills is demonstrated, then diffusion policy learns in the background overnight, and the resulting robots are reported to perform dozens of diverse behaviors. The broader goal is “large behavior models,” analogous to large language models, with plans to expand from tens to hundreds and eventually thousands of behaviors, aided by simulation and fleet learning.
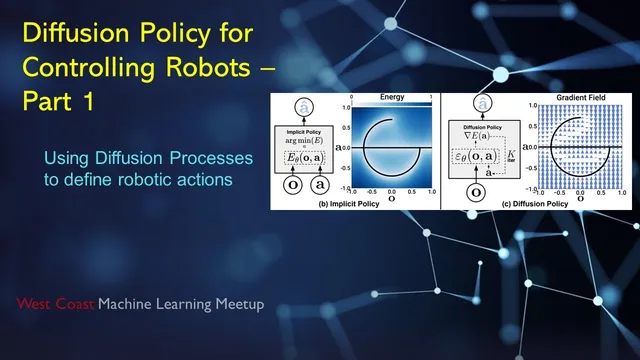
The meeting then breaks down how diffusion works in low-dimensional toy settings to build intuition for the robot version. In these examples, probability mass concentrates along structures like a Swiss roll, and a learned “score function” (the gradient of the log probability) guides many samples from an initial random distribution toward high-density regions. A key clarification is that the score function is effectively a gradient field used during inference: start with noise, repeatedly take stochastic steps guided by the learned gradient, and the samples converge to plausible outputs. For robotics, the output is not pixels but actions—often a time-ordered sequence—so the diffusion process is used to generate temporally consistent control signals rather than a single step.
From the paper’s abstract and the discussion, diffusion policy is described as learning the gradient of the action distribution and optimizing action sequences during inference through a series of stochastic updates. The approach is contrasted with: - Energy-based/implicit policies, which can be harder to train because they require dealing with normalization terms (and negative sampling inaccuracies can destabilize learning). - Imitation baselines like behavior cloning and behavior transformers, which may be biased toward one mode of a multimodal solution (e.g., choosing only the left or only the right way around an obstacle) and can struggle with sharp action changes. - LSTM-style implicit policies that directly regress actions from observations, avoiding explicit probability modeling but potentially losing multimodality.
Architecturally, the system uses either a CNN-based score network or a “time series diffusion Transformer.” The CNN variant uses a ResNet-18 visual encoder (trained end-to-end rather than relying on pretraining) and applies feature-wise linear modulation to condition on observations. The Transformer variant uses attention over observation tokens and masks attention over action history to generate future actions step-by-step within the diffusion refinement loop. A central control strategy is “receding horizon control”: the model plans a short action chunk from current observations, executes only part of it, then replans after new observations arrive—balancing responsiveness with temporal smoothness.
Empirically, the discussion cites 12 tasks and reports an average 46% improvement in successful completion over state-of-the-art methods, with diffusion policy especially noted for handling multimodal action distributions and for training stability. The practical takeaway is that diffusion policy can generate plausible, consistent action trajectories under uncertainty—without requiring explicit programming of each skill—while remaining responsive enough for real-time robot control through chunked planning and replanning.
Cornell Notes
Diffusion policy reframes robot control as a conditional denoising diffusion process. Instead of outputting a single action, it generates a short time-ordered sequence of future actions by starting from noise and iteratively refining the sequence using a learned score function (gradient of the log action distribution). During execution, receding horizon control is used: the robot plans several steps ahead, executes only part of that plan, then replans from fresh observations to stay responsive. The approach is reported to improve success rates across multiple benchmarks (12 tasks) and to better handle multimodal action choices (e.g., going left vs. right) than several imitation-learning baselines. It also avoids some training instability seen in energy-based implicit policies that require normalization or rely on negative sampling.
How does diffusion policy’s “score function” guide action generation during inference?
Why does generating a sequence of actions matter for multimodal control?
What is receding horizon control in this setting, and how does it affect responsiveness?
What architectural choices are used for the diffusion policy’s score network?
Why is training stability a differentiator versus energy-based implicit policies?
How do the state-policy and vision-policy setups differ in practice?
Review Questions
- What does the model condition on when generating action sequences, and how does that conditioning enter the CNN-based vs Transformer-based score networks?
- Explain receding horizon control and why it can reduce both flip-flopping and latency compared with predicting and executing a full long plan at once.
- Compare diffusion policy to an energy-based implicit policy: what training difficulty arises from normalization/negative sampling, and why does diffusion avoid it?
Key Points
- 1
Diffusion policy treats robot control as a conditional denoising diffusion process that generates short action sequences rather than single-step actions.
- 2
A learned score function (gradient of the log action distribution) drives iterative refinement from noisy action trajectories toward high-probability behaviors.
- 3
Receding horizon control enables chunked planning and replanning, improving responsiveness while maintaining temporal consistency.
- 4
The approach is reported to handle multimodal action distributions better than baselines that may collapse to one mode (e.g., only one side of a route).
- 5
CNN-based and Transformer-based score networks are both used, with FiLM-style conditioning for the CNN variant and masked attention for the time series Transformer variant.
- 6
Training stability is a key claimed advantage over energy-based implicit policies that rely on normalization terms and negative sampling.
- 7
Reported results include an average 46% improvement across 12 tasks, with diffusion policy especially strong on tasks requiring dexterous, contact-rich manipulation.