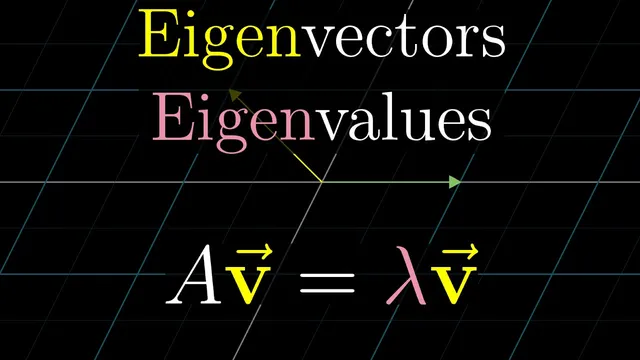
Eigenvectors and eigenvalues | Chapter 14, Essence of linear algebra
Based on 3Blue1Brown's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Eigenvectors are the nonzero vectors v that satisfy A v = λ v, so the transformation maps v to a scalar multiple of itself without rotating it off its span.
Briefing
Eigenvectors are the vectors that stay on their own span under a linear transformation—meaning the transformation only stretches or squishes them, without rotating them away. That “stay on the same line” property turns an otherwise opaque matrix action into something geometric and often easier to reason about. In a 2D example where the matrix sends the x-axis to itself with a scale factor of 3, every vector on the x-axis remains aligned with its original span and gets multiplied by 3. A second special line appears too: vectors along the diagonal direction through (−1, 1) also stay on their own span, but they scale by 2 instead. Everything else gets rotated off its original line, which is why it doesn’t qualify as an eigenvector.
The practical payoff is that eigenvectors and eigenvalues capture the “core behavior” of a transformation in a coordinate-system-independent way. Instead of reading off what the matrix does to basis vectors (which depends on the chosen coordinates), eigenvectors reveal directions that the transformation treats predictably. The eigenvalue is the exact scaling factor: positive values stretch, negative values flip, and fractional values squish. For instance, a 3D rotation has eigenvalue 1 along its rotation axis, because vectors on that axis keep their length and direction relative to their span. Finding that eigenvector identifies the axis of rotation, which is far more intuitive than working directly with a full 3×3 rotation matrix.
Computing eigenvectors and eigenvalues boils down to solving the equation A v = λ v, where A is the matrix, v is a nonzero vector, and λ is the eigenvalue. The key algebra move is rewriting this as (A − λI)v = 0, with I the identity matrix. A nontrivial solution exists only when A − λI “squishes space” into a lower dimension, which corresponds to det(A − λI) = 0. That determinant condition produces a polynomial in λ; its roots are the eigenvalues. Once λ is known, the eigenvectors come from solving the resulting linear system (A − λI)v = 0.
A concrete 2D case illustrates the workflow: for a matrix with columns (3,0) and (1,2), subtracting λ along the diagonal and taking the determinant yields a quadratic whose zeroes are λ = 2 and λ = 3. Plugging λ = 2 back into (A − λI)v = 0 produces eigenvectors exactly along the line spanned by (−1,1), matching the earlier geometric claim that those vectors scale by 2.
Not every transformation has real eigenvectors. A 90° rotation in 2D has a characteristic polynomial λ² + 1, whose roots are imaginary (±i), so no real eigenvectors exist—every real vector gets rotated off its span. Shears show a different pattern: the x-axis vectors are eigenvectors with eigenvalue 1, and in that example they are the only eigenvectors. Meanwhile, some matrices have an eigenvalue shared by every vector; scaling by 2 has eigenvalue 2 everywhere.
Finally, when eigenvectors form a full spanning set, they define an eigenbasis. In that basis, the transformation becomes diagonal, with eigenvalues sitting on the diagonal. Diagonal matrices make repeated powers easy: applying the matrix 100 times raises each eigenvalue to the 100th power along its eigenvector direction. If an eigenbasis exists, switching to it via a change-of-basis matrix can turn difficult computations into straightforward scaling—though transformations like shears lack enough eigenvectors to span the whole space, so the diagonalization shortcut fails there.
Cornell Notes
Eigenvectors are the nonzero vectors v that satisfy A v = λ v, meaning the linear transformation A maps v to a scalar multiple of itself. Geometrically, this says v stays on the same line (its span) under the transformation; the scalar λ is the eigenvalue. To find eigenvalues, rewrite the condition as (A − λI)v = 0 and require a nontrivial solution, which happens exactly when det(A − λI) = 0. The determinant gives a polynomial in λ whose roots are the eigenvalues; solving (A − λI)v = 0 then yields the eigenvectors. When enough eigenvectors exist to form a basis (an eigenbasis), the matrix becomes diagonal in that basis, making powers like A^100 easy to compute.
Why do eigenvectors matter more than just tracking where basis vectors land?
How does the equation A v = λ v turn into a determinant condition?
In the 2D example with matrix columns (3,0) and (1,2), how do eigenvalues and eigenvectors emerge?
Why does a 90° rotation in 2D have no real eigenvectors?
What makes an eigenbasis so useful for computing powers of a matrix?
Review Questions
- Given a matrix A, what steps convert the eigenvector condition A v = λ v into det(A − λI) = 0?
- How would you interpret a negative eigenvalue geometrically for an eigenvector?
- What does it mean for a transformation to have no real eigenvectors, and how can you tell from the characteristic polynomial?
Key Points
- 1
Eigenvectors are the nonzero vectors v that satisfy A v = λ v, so the transformation maps v to a scalar multiple of itself without rotating it off its span.
- 2
Eigenvalues λ are the exact stretch/squish factors: positive stretches, negative flips, and fractional values squish while preserving the eigenvector direction.
- 3
Finding eigenvalues reduces to solving det(A − λI) = 0, because nontrivial solutions to (A − λI)v = 0 require A − λI to be singular.
- 4
Once an eigenvalue λ is found, eigenvectors come from solving (A − λI)v = 0 as a standard linear system.
- 5
A transformation may have no real eigenvectors (e.g., a 90° rotation in 2D) when the characteristic polynomial has only imaginary roots.
- 6
If eigenvectors span the space (an eigenbasis), the matrix becomes diagonal in that basis, making powers like A^100 straightforward via λ^100 scaling.
- 7
Some transformations (like shears) lack enough eigenvectors to form an eigenbasis, so diagonalization via eigenvectors is not available.