Feedback Loops in Opinion Modeling | Danielle Ensign | OpenAI Scholars Demo Day 2021
Based on OpenAI's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Self-feeding feedback loops can destabilize opinion modeling by driving models toward either low-diversity collapse or high-entropy randomness.
Briefing
Feedback loops in opinion modeling can drive language models toward “collapse” or runaway randomness when their generated outputs get fed back into future training or sampling. The core finding is that iterative self-feeding—especially under temperature-based sampling—reduces diversity over time, either locking the system onto a narrow set of outputs (mode collapse) or pushing it toward near-maximum entropy behavior. That matters for AI safety and fairness because it can reshape preferences and the “opinion ecosystem” without any explicit intent, potentially amplifying technical bias (and possibly real-world bias) as models become increasingly tuned to their own quirks.
The work starts by framing why opinion modeling needs dynamics, not just static snapshots. Traditional language modeling learns from large datasets to represent a moment in time, but it misses how preferences evolve. Prior approaches include simulation-style studies (e.g., social or code ecosystems), agent-based/system-theory models that struggle with choosing the right granularity, and network-based analyses that track how data moves through opinion structures. Against that backdrop, the study targets a specific mechanism: models that output data which then becomes training or sampling input for later models.
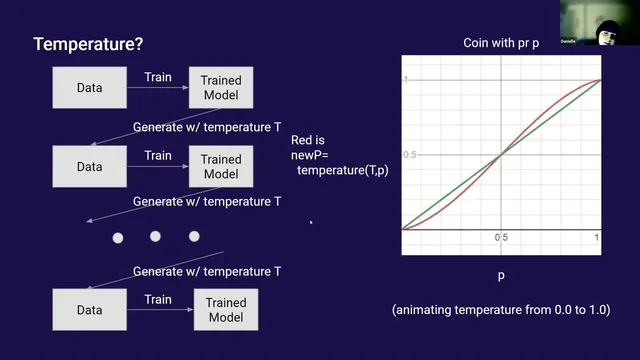
A formal setup repeats a simple loop: train a model on some data, generate new data, use that generated data to train another model (or fine-tune), then repeat. To build intuition, the presenter analyzes a discrete “coin flip” toy model. With repeated sampling and retraining, the system can drift until it becomes stuck on one outcome—an absorbing state—because the model may repeatedly output the same token, making that token increasingly likely. Two key theoretical insights emerge: more data tends to reduce the effective step size (slowing change), and stochastic dynamics can still end in extreme collapse.
Temperature—the sampling knob that reshapes probabilities—turns out to be central. Temperature effectively pushes probabilities above 0.5 upward and below 0.5 downward, which can perpetuate existing biases and accelerate collapse. In the toy analysis, collapse corresponds to the system converging to a single path with no cycles; cycles represent competing trajectories that eventually get eliminated.
When the same question is tested on n-gram models, the expected collapse pattern appears: after many iterations, the process converges to a narrow sequence with no cycling. Transformers introduce complications because collapse is harder to measure directly, so the study uses entropy as a proxy. By generating many sentences and estimating entropy from word-by-word probabilities, the analysis finds two regimes. In one, entropy shoots toward high randomness and the model behaves like a near-uniform generator. In the other, entropy rises initially and then falls into collapse, accompanied by repetitive loops in generated text (e.g., short back-and-forth repetitions or repeated phrases). The system becomes “used to” outputs that are weirder than its original inputs, and once a loop appears, it becomes self-reinforcing.
Temperature thresholds align with the observed behavior: below roughly 1.0, collapse happens quickly; above 1.0, the system tends toward maximum entropy. The presenter also discusses mitigation and next steps, including “grounding” feedback—mixing real data with model-generated data so the random walk is biased toward a stable distribution. Questions raised in the Q&A emphasize open issues: whether entropy always increases then decreases, how grounding would behave in real language models, and how much mixing is needed when only a few feedback iterations occur.
Cornell Notes
Iterative opinion modeling that feeds a model’s own generated outputs back into later training or sampling can produce two unstable outcomes: diversity collapse or runaway randomness. In discrete toy settings, repeated self-feeding can drive the system toward absorbing states where one token dominates, and temperature accelerates this by sharpening probability mass. N-gram experiments show collapse into a single path, while transformer experiments use entropy estimates to reveal two regimes: entropy can either rise toward maximum randomness or rise then fall into collapse with repetitive cycles. Temperature below about 1.0 leads to faster collapse; above about 1.0 tends toward high-entropy behavior. The work suggests that grounding—mixing real data into the feedback loop—could stabilize the process, though it remains unvalidated for full language models.
What is the mechanism behind “collapse” in self-feeding opinion modeling?
How does temperature change the dynamics of feedback loops?
Why do transformer experiments rely on entropy rather than a direct “collapse” metric?
What two regimes appear when transformer outputs are fed back into training/sampling?
How might “grounding” mitigate feedback-loop instability?
What does the Q&A suggest about practical relevance and iteration counts?
Review Questions
- In the coin-flip toy model, what causes the system to reach an absorbing state, and how does that relate to token repetition in language generation?
- How does temperature influence whether feedback loops lead to entropy growth versus entropy decline in transformer experiments?
- What role does grounding (mixing real data with model-generated data) play in stabilizing the feedback process, and why might it be especially important when only a few iterations occur?
Key Points
- 1
Self-feeding feedback loops can destabilize opinion modeling by driving models toward either low-diversity collapse or high-entropy randomness.
- 2
Temperature acts as a probability-sharpening mechanism that can accelerate collapse by making dominant outputs more self-reinforcing.
- 3
Discrete toy dynamics show how repeated sampling can create absorbing states where one token/outcome dominates.
- 4
N-gram models exhibit collapse into a single path with no cycles, matching theoretical expectations about eliminating competing trajectories.
- 5
Transformer experiments reveal two entropy regimes when generated outputs are fed back: high-entropy runaway or entropy rise followed by collapse with repetitive cycles.
- 6
Grounding—mixing real data into the feedback loop—can bias the system toward stable distributions and may prevent collapse, though results for full language models remain open.
- 7
Practical deployments likely run only a few feedback steps, so even small amounts of grounding data could have outsized effects.