Frameworks & Distributed Training (5) - Infrastructure & Tooling - Full Stack Deep Learning
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Frameworks have converged toward Python-first development with optimized execution graphs for production, reducing the earlier development-vs-deployment tradeoff.
Briefing
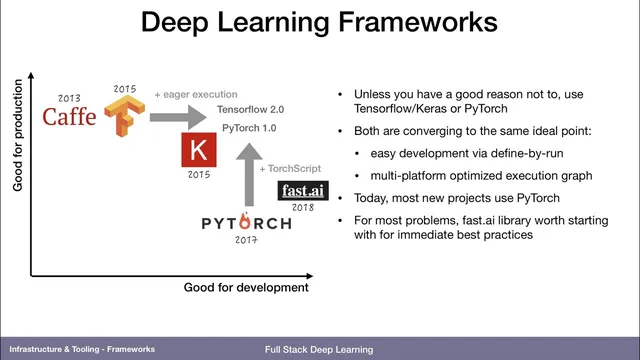
Deep learning frameworks have shifted from “fast in production, painful in development” toward a convergence where developers write in Python with immediate feedback, while the system still produces optimized execution graphs for deployment. Early ecosystems split along a two-axis tradeoff: Caffe (written in C++ at Berkeley) delivered high performance and straightforward GPU/CUDA execution, but adding new layer types or wiring unusual computation graphs required C++ work and manual backward implementations. TensorFlow (2015) improved hardware portability and production readiness, yet its original static-graph style required describing computation indirectly, making iteration and debugging harder.
Keras (built on top of TensorFlow and other libraries like Theano) made model building more ergonomic by letting developers declare models with less graph “meta-programming,” but the core runtime still reflected TensorFlow’s graph-first approach. PyTorch (2017) flipped the development experience by executing the forward pass directly in Python, enabling standard debugging workflows such as breakpoints inside model code. That development-first design raised production concerns—until TensorFlow added eager execution and PyTorch introduced TorchScript, an optimized execution graph that can run efficiently on constrained systems, including mobile.
In practice, most new projects start with PyTorch, with TensorFlow 2.0 (released recently relative to the discussion) serving as an upgrade path for older TensorFlow 1.x models. The training ecosystem also matters: fastai provides training utilities—learning-rate finding and out-of-the-box model components—so teams can begin with strong defaults and diverge only when needed. Research and hiring signals reinforce the momentum: an academic analysis (“the gradient”) found PyTorch mentions rising sharply in major machine learning conferences (from near zero to close to 80% over a few years), while TensorFlow and Keras still lead job posts but lag research workflows.
The discussion then pivots to distributed training, where a single training run uses multiple GPUs or multiple machines to reduce iteration time—especially when datasets or models are too large for quick single-device passes. Two strategies dominate. Data parallelism replicates the model on each GPU and splits each batch across devices; after backprop, gradients synchronize so weights stay tied. For convolutional networks, speedups are close to linear at small scales (roughly 2 GPUs ~1.8–2x, 4 GPUs ~3–3.5x), though not perfectly linear.
Model parallelism becomes necessary only when the model cannot fit in one GPU’s memory, partitioning the model graph so different weights live on different devices. It’s more complex and generally not worth it unless memory constraints force the issue.
Framework support makes data parallel relatively straightforward: TensorFlow’s Distributed Mirrored Strategy and PyTorch’s data-parallel wrapping can automatically split batches and synchronize weights. Multi-machine distribution is harder because it introduces parameter servers and inter-process coordination. That’s where tools like Ray (for stateful distributed computing in Python) and Horovod (Uber’s approach using MPI instead of TensorFlow’s parameter-server machinery) enter as practical alternatives. The Q&A also highlights a recurring bottleneck: data loading. Best practice is to lean on framework-native input pipelines—TFRecord and TensorFlow’s TF data API in TensorFlow, or PyTorch’s DataLoader—then tune prefetching and disk/cloud-to-GPU transfer timing to keep GPUs fed. Overall, the infrastructure goal is to make scaling easier than it used to be, with distributed training increasingly feasible as frameworks and tooling mature—setting up a later comparison with managed platforms like SageMaker.
Cornell Notes
Deep learning tooling has moved toward a “write in Python, run efficiently” middle ground. PyTorch popularized development-friendly eager execution, while TensorFlow added eager execution and PyTorch added TorchScript to produce optimized graphs for deployment, including constrained devices. Most new work favors PyTorch, supported by libraries like fastai that provide training utilities and strong starting models. For scaling training, distributed training mainly uses data parallelism (replicate model, split batches, synchronize gradients) for speedups, while model parallelism is reserved for cases where a model won’t fit in a single GPU. Multi-machine setups are harder, so Ray and Horovod are often used to simplify distributed execution and communication.
Why did early frameworks feel so different for development versus production?
What changed so that PyTorch and TensorFlow started converging?
When should teams choose data parallelism versus model parallelism?
How do frameworks make data parallelism easier to implement?
What makes multi-machine distributed training harder, and what tools help?
Why does data loading often become the bottleneck, and what’s the recommended approach?
Review Questions
- What specific mechanisms (eager execution and TorchScript) drive the convergence between PyTorch and TensorFlow, and how do they affect debugging versus deployment?
- In distributed training, what must be synchronized in data parallelism, and why does model parallelism usually carry higher complexity?
- What practical steps can reduce GPU idle time caused by slow data loading, and which framework-native tools support those steps?
Key Points
- 1
Frameworks have converged toward Python-first development with optimized execution graphs for production, reducing the earlier development-vs-deployment tradeoff.
- 2
Caffe’s C++ layer system and manual backward implementations made extension harder, while TensorFlow’s original static-graph approach made iteration and debugging less direct.
- 3
PyTorch’s eager execution improved debugging workflows, and TorchScript later enabled optimized graph execution for mobile and constrained environments.
- 4
Distributed training mainly uses data parallelism for speedups by splitting batches across GPUs and synchronizing gradients, while model parallelism is reserved for models that don’t fit in one GPU’s memory.
- 5
Single-machine multi-GPU data parallel is often easy via framework strategies/wrappers, but multi-machine training adds coordination complexity such as parameter servers.
- 6
Ray and Horovod are practical options for multi-machine distributed training, with Horovod leveraging MPI to avoid some of TensorFlow’s parameter-server friction.
- 7
Data loading frequently limits throughput; using framework-native input pipelines (TFRecord/TF data API, DataLoader) and tuning prefetch/transfer timing is key to keeping GPUs busy.