Generative AI Project Lifecycle-GENAI On Cloud
Based on Krish Naik's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Start by defining the GenAI use case (RAG, summarization, chatbot) and scope the required components and data needs.
Briefing
Generative AI projects on cloud follow a repeatable lifecycle: define the business use case, choose and adapt the right model, evaluate it, then deploy and integrate it into applications. The practical payoff is straightforward—teams can move from raw requirements to an inference-ready system without skipping the steps that usually cause quality, cost, or latency problems.
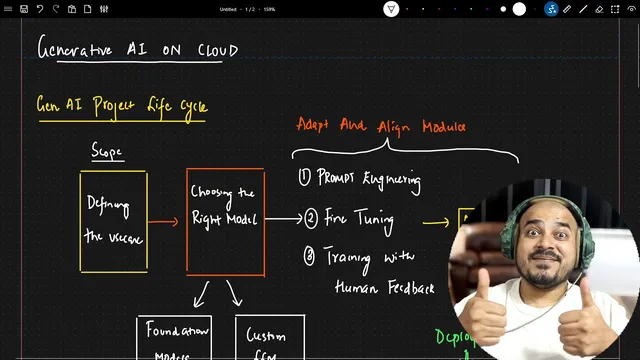
The lifecycle starts with use-case definition. Whether the target is a RAG application, a text summarization system, or a chatbot, the work begins by scoping what the solution must do and what data and components it needs. For example, a RAG workflow typically requires converting documents (like PDFs) into embeddings and storing them in a vector database so the system can retrieve relevant context at runtime.
Next comes the most consequential decision: selecting the right model approach. Teams can either use foundation models—large prebuilt models such as OpenAI, Llama 2, Llama 3, or Google’s Gemini Pro—or build a custom LLM from scratch. Foundation models can also be adapted further using fine-tuning so the model behaves better on a company’s specific data. Building a custom LLM can deliver tighter control for specialized use cases, but it demands significant resources and careful handling of issues like hallucinations.
After model selection, the workflow shifts to adapting and aligning models through three main techniques: prompt engineering and prompt-based solving, fine-tuning, and training with human feedback (a key method for teaching models to follow instructions and reduce undesirable outputs). Once adaptation is done, evaluation becomes the gatekeeper. Performance metrics must show improvement—only then does the model qualify as “ready” for real-world use.
Deployment is where cloud engineering turns a working model into a usable service. Deployment requires integration with applications and optimization for inference speed and reliability. This is also where LLM Ops enters the picture, since it supports production-grade inference patterns and operational concerns. The transcript emphasizes that multiple inference strategies matter because a model that isn’t fast enough can’t serve users effectively. The focus is initially on AWS, with mention that Azure and GCP also provide services for inference, and that teams should learn the options each cloud offers.
Finally, once APIs and integration are in place, the project moves into building LLM-powered applications—turning the deployed model into end-to-end solutions that solve the original business problems. The overall message is that cloud-based GenAI development isn’t just about training or fine-tuning; it’s about building a pipeline from use-case scope to inference-ready deployment and application integration, with evaluation and LLM Ops treated as first-class steps.
Cornell Notes
The GenAI project lifecycle on cloud is organized into a sequence: define the use case, choose the right model strategy, adapt/align it, evaluate performance, then deploy and integrate it into applications. Use-case scoping determines whether the system is RAG, summarization, or a chatbot, and RAG typically requires embedding documents and storing them in a vector database. Model choice can rely on foundation models (with optional fine-tuning) or on building a custom LLM from scratch, which is resource-intensive and requires managing issues like hallucinations. Adaptation and alignment typically use prompt engineering, fine-tuning, and training with human feedback. After evaluation confirms improved metrics, deployment focuses on inference optimization and LLM Ops, followed by application integration and building LLM-powered products.
How does defining the use case shape the rest of a GenAI project lifecycle?
What are the two main paths for model selection, and when does each make sense?
Which techniques are used to adapt and align models after choosing them?
Why does evaluation come before deployment, and what does it measure?
What does deployment require in cloud GenAI systems, and why is inference optimization central?
After deployment, what work remains to turn a model service into a working product?
Review Questions
- What decision points in the lifecycle determine whether a RAG system needs vector database storage and embedding pipelines?
- Compare foundation model fine-tuning with building a custom LLM from scratch in terms of resource demands and quality risks.
- Why must evaluation metrics improve before deployment, and how does inference optimization affect real-world usability?
Key Points
- 1
Start by defining the GenAI use case (RAG, summarization, chatbot) and scope the required components and data needs.
- 2
Choose between foundation models (optionally fine-tuned) and custom LLMs built from scratch, balancing capability against cost and risk.
- 3
Adapt and align models using prompt engineering, fine-tuning, and training with human feedback.
- 4
Evaluate with performance metrics and only proceed when results show measurable improvement.
- 5
Deploy by integrating the model into applications and optimizing for inference speed and reliability.
- 6
Use LLM Ops to support production-grade inference operations and operational workflows.
- 7
After deployment, build the LLM-powered application layer that turns APIs into end-to-end solutions.