GPT-4 Tutorial: How to Chat With Multiple PDF Files (~1000 pages of Tesla's 10-K Annual Reports)
Based on Chat with data's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Convert each PDF to text, then chunk it to fit model context limits before embedding.
Briefing
Answering questions across multiple massive PDF files—like several years of Tesla 10-K annual reports—becomes practical when each document is converted into searchable embeddings and the system can dynamically route a user’s question to the right year-specific “namespace” in a vector database. The core payoff: a single chat can retrieve relevant passages from 2020, 2021, and 2022 reports, then compute or summarize across them while citing the underlying page sources.
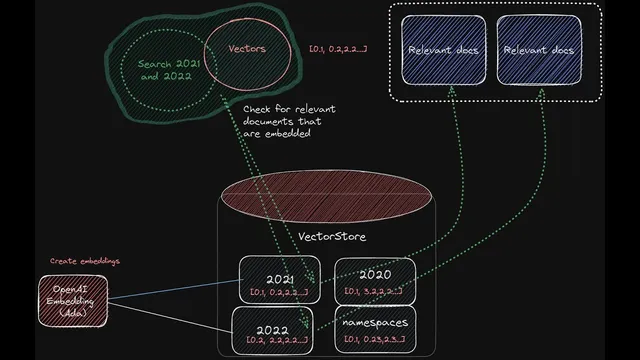
The workflow starts with ingestion. Each PDF is converted from binary into text, then split into chunks because models only handle limited context at a time. Those chunks are embedded into numeric vectors (representations of meaning) and stored in a vector store so retrieval can happen fast. The design uses separate namespaces per year—e.g., Tesla 2020, Tesla 2021, Tesla 2022—so the system can search within the correct subset of documents. Pinecone is used as the vector store, and the embeddings dimension must match the embedding model output (the transcript notes 1536 for OpenAI embeddings). During ingestion, metadata such as page numbers and source references are attached to chunks so answers can be grounded with citations.
Query-time logic is where multi-year analysis is made to work. For a single-year question, the system can search one namespace directly. But cross-year questions require a routing strategy: the system must determine which years the user is referring to, then search multiple namespaces and combine the retrieved context. To avoid hard-coding, GPT-4 is used to extract the years from the user’s question (via a function that returns the referenced years). Those years are mapped to the corresponding namespaces. Once the relevant namespaces are identified, the system retrieves top-matching chunks from each, merges the context, and sends it to GPT-4 to produce a synthesized answer.
The transcript demonstrates this with finance-style prompts such as “What were the risk factors for Tesla 2022?” (with page-level references) and then escalates to questions spanning multiple years, like gross margin changes over three years and revenue growth calculations. In the multi-year case, the system not only pulls supporting excerpts from each annual report but also performs arithmetic based on the retrieved statements (for example, computing revenue growth using consolidated statement figures). The demo also references a front-end and API adaptation, with LangChain chains orchestrating the steps: extracting years, retrieving from Pinecone namespaces, and generating the final response.
Implementation details reinforce operational realism: ingestion is done via scripts that load PDFs from a reports folder, chunk them (the transcript mentions chunk sizes and overlap), and insert vectors in batches because Pinecone has limits (the transcript notes a recommendation around 100 vectors per insert). The result is an architecture that can chat over roughly a thousand pages across multiple PDFs while keeping answers tied to the original documents—turning tedious reading into targeted, source-cited analysis across time.
Cornell Notes
The system turns each year’s Tesla 10-K PDFs into text chunks, embeds those chunks into vectors, and stores them in a vector database (Pinecone) under year-specific namespaces (e.g., Tesla 2020, Tesla 2021, Tesla 2022). When a user asks a question, GPT-4 extracts which years are referenced, maps those years to the matching namespaces, retrieves the most relevant chunks from each, and then generates a combined answer with citations to the source pages. This dynamic namespace routing is what enables cross-year analysis instead of only single-PDF Q&A. Page numbers and source references are preserved as metadata during ingestion so the final responses can be checked against the original filings.
Why convert PDFs into embeddings and store them in a vector database?
What problem does “namespaces per year” solve?
How does the system handle questions that mention multiple years without hard-coding?
How are citations and page references preserved?
What operational constraints matter when inserting vectors into Pinecone?
What kinds of questions work best in this setup?
Review Questions
- How does dynamic year extraction change the retrieval process compared with a fixed single-namespace approach?
- Describe the ingestion pipeline from PDF to Pinecone, including chunking and metadata. Why is chunking necessary?
- What configuration details (e.g., embedding dimension, index name, environment) must match between code and Pinecone for insertion and retrieval to work?
Key Points
- 1
Convert each PDF to text, then chunk it to fit model context limits before embedding.
- 2
Store embeddings in Pinecone under year-specific namespaces so retrieval can be scoped to the right annual report.
- 3
Use GPT-4 to extract which years a user’s question references, then map those years to the correct namespaces dynamically.
- 4
Retrieve relevant chunks from each identified namespace, merge the context, and generate a synthesized answer with citations.
- 5
Attach page numbers and source references as metadata during ingestion so answers can be cross-checked in the original filings.
- 6
Insert vectors in batches to respect Pinecone limits, and ensure embedding dimensions and Pinecone configuration match the code.
- 7
Use LangChain chains to orchestrate year extraction, vector retrieval, and final GPT-4 response generation.