GPT-4 Vision: How to use LangChain with Multimodal AI to Analyze Images in Financial Reports
Based on Chat with data's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Partition PDFs into text, tables, and images using Unstructured so each modality can be handled separately.
Briefing
Financial reports often hide the real answers inside tables, charts, and other images—not in the surrounding text. The core takeaway is a practical multimodal RAG pattern for those documents: embed a plain-language summary of each image for retrieval, then pass the original raw image to a multimodal LLM (like GPT-4V) for the final answer. This “decouple what you search from what you read” approach is positioned as the most effective option today for dense finance visuals where generic multimodal embeddings struggle.
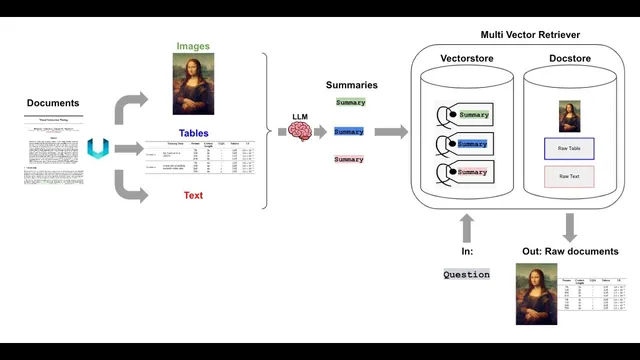
The workflow starts with document partitioning. Using Unstructured, the system splits PDFs into text elements, table elements, and extracted images. From there, each text chunk and each table (and each image) gets a summary generated by a model such as GPT-4V. Those summaries are embedded into a vector store for similarity search. Crucially, the raw content—the original images and the raw text/table chunks—are stored separately in a document store (a key-value “doc store”). A Multivector retriever links the summary embeddings to the raw items via a shared ID: retrieve by summary, then look up and return the raw image/text/table.
Three architectural options are compared. The first uses multimodal embeddings that map images and text into the same embedding space; it preserves information but is limited by the current availability and quality of multimodal embedding models for complex charts and tables. The second converts images to text summaries, embeds those summaries, and answers using only text; it’s easy to plug into standard RAG stacks but can be lossy. The third—summarize images for retrieval, return the raw images for the final multimodal reasoning—is presented as the best balance of retrieval accuracy and answer fidelity.
Concrete examples focus on finance questions that require reading tables. For a query about “revenue multiples and growth” across companies, the retrieved image summary points to a specific table image containing NTM revenue and growth metrics. GPT-4V then extracts the requested values and produces a structured answer (with values sanity-checked). Another example asks for company names based on “multiples and growth” while considering historical trends; retrieval brings back multiple images (a current multiples table and historical trend visuals), and GPT-4V synthesizes recommendations using both chart-level and table-level evidence.
The discussion also highlights engineering constraints and failure modes. Image size matters: images must be large enough to preserve table/chart detail but small enough to avoid GPT-4V rate-limit issues; resizing is treated as a key preprocessing step. Chunking still matters for text: too many small, redundant text chunks can “soak up” similarity and crowd out image retrieval, so larger text chunks (e.g., ~4K tokens) with summaries are used to keep retrieval balanced across modalities. For production, the doc store can be external (e.g., Redis-like key-value storage), and the multivector retriever concept is described as compatible with different vector stores as long as the summary-to-raw lookup mechanism is implemented.
Overall, the approach reframes multimodal RAG as a retrieval-optimized indexing problem: summaries act as searchable handles, while the multimodal LLM remains the final reader of the original images and tables. Evaluation work and public datasets are flagged as the next step to quantify tradeoffs and tune parameters like chunk size and image preprocessing.
Cornell Notes
Multimodal financial documents contain key facts inside images—especially tables and charts—so retrieval must work across modalities. A strong pattern is to generate a plain-language summary for each image (and table/text chunk), embed those summaries for vector search, and retrieve by summary. After retrieval, the system uses the shared ID to fetch the raw image from a separate doc store and sends the raw image (plus relevant text) to a multimodal LLM like GPT-4V for final answer synthesis. This “embed summaries, read raw images” design improves retrieval for dense visuals where direct multimodal embedding retrieval can miss table/chart nuance. It still requires careful preprocessing: image resizing and text chunking to avoid redundant text crowding out image retrieval.
Why not embed images directly for retrieval in finance RAG?
What are the three main architectures for adding images to RAG?
How does the Multivector retriever connect image summaries to raw images?
What preprocessing choices most affect performance?
How does the system answer table-heavy questions end-to-end?
How can metadata filtering or routing work with this architecture?
Review Questions
- What problem does the “embed summaries, retrieve raw images” design solve compared with direct multimodal embedding retrieval?
- Describe the role of the doc store and the shared ID in the Multivector retriever pipeline.
- Which two preprocessing steps (image sizing and text chunking) most influence whether images are retrieved and why?
Key Points
- 1
Partition PDFs into text, tables, and images using Unstructured so each modality can be handled separately.
- 2
Generate plain-language summaries for images (and tables/text chunks) and embed those summaries for similarity search.
- 3
Store raw images (and raw text/table chunks) in a separate doc store and link them to summary embeddings using a shared ID.
- 4
Use Multivector retriever to retrieve by summary similarity, then return raw images to GPT-4V for final answer extraction and reasoning.
- 5
Direct multimodal embedding retrieval is currently less reliable for dense finance tables/charts than the summary-retrieval + raw-image-reading approach.
- 6
Resize images to balance detail preservation against GPT-4V rate-limit behavior when sending multiple images.
- 7
Tune text chunking to prevent redundant small chunks from dominating similarity search and crowding out image retrieval.