Graph Analysis - The Basics
Based on Obsidian Community Talks's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Graph Analysis distinguishes structural algorithms (link-structure only) from NLP algorithms (word/content-based), and the best workflow depends on which signal you want.
Briefing
Graph Analysis for Obsidian turns a vault’s link structure—and, when enabled, note text—into a set of measurable relationships that help surface “what connects to what” across hundreds or thousands of notes. The practical takeaway is that the plugin’s numbers matter less than the rankings and relative patterns: if one note consistently scores higher than another, that difference often points to a meaningful connection worth checking.
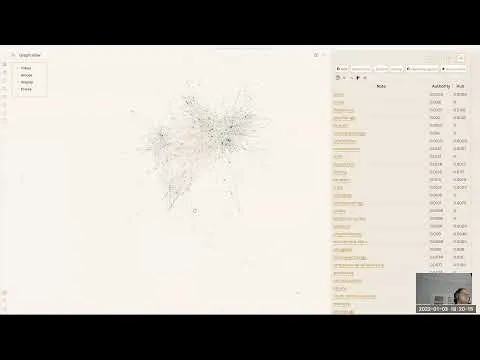
After installing Graph Analysis from Obsidian’s community plugins and opening the “Graph Analysis View,” users can run algorithms against a selected note and see ranked results in a new pane. The plugin distinguishes between structural algorithms, which rely only on the graph of links between notes, and natural-language-processing (NLP) algorithms, which analyze the actual words inside notes. A key usability point is that many algorithms can generate large tables of values; the workflow is designed for scanning relationships—sorting, jumping to linked notes, and using hover previews—rather than treating exact scores as absolute truth.
Structural algorithms come in several families. Link prediction algorithms estimate how likely any other note is to be connected to the currently focused note based purely on graph structure; results can be cross-checked with icons that indicate whether a predicted connection already exists. Similarity algorithms also work from structure, measuring how alike two notes are by comparing neighbor overlap; one example uses a neighbor-overlap ratio that ranges from 0 to 1, highlighting cases where notes are similar enough that a link “should” exist even if it doesn’t. Centrality algorithms identify influential nodes in the network. The plugin’s HITS implementation reports both hub and authority scores: authority rises for notes with many incoming links, while hub rises for notes with many outgoing links. These HITS results are global, meaning they don’t change when the focused note changes.
Community detection algorithms cluster notes into groups based on connectivity patterns. Label propagation assigns each node a starting label and iteratively spreads the most common labels through the graph; after a configurable number of iterations, notes settle into communities. A second community method, Louvain, behaves differently: it’s local to the currently focused note and includes randomness, so refreshes can shift membership. The clustering coefficient algorithm adds another structural lens by estimating how likely a node’s neighbors are connected to one another—capturing “triangle” behavior that can hint at tightly knit subtopics.
A “freeze” control helps manage non-global algorithms by locking results to the currently focused note, so users can browse elsewhere without the ranking changing. For content-based analysis, Graph Analysis can also run NLP algorithms, but it requires a separate NLP plugin. Once enabled (and after an initial indexing delay), NLP features include bag-of-words similarity, a second content-based similarity method (provided by the NLP library), a Monte Carlo method, and sentiment analysis. Sentiment analysis is global and assigns each note a positive/negative score, making it easy to spot outliers such as highly negative notes.
Finally, Graph Analysis includes practical configuration: selecting which algorithms appear by default, excluding notes via tags or regular expressions (including matching against full file paths), optionally including non-Markdown files (images, videos, PowerPoint, etc.), and optionally including unresolved links. The overall message is straightforward: start with quick structural insights, then layer NLP for content-level signals when needed—using relative comparisons to guide exploration rather than obsessing over exact values.
Cornell Notes
Graph Analysis for Obsidian uses algorithms to measure relationships between notes, primarily from the vault’s link structure and optionally from note text. Structural methods include link prediction, similarity (neighbor overlap), centrality (HITS hub/authority), community detection (label propagation and Louvain), and clustering coefficient. NLP methods require a separate NLP plugin and add content-based similarity (bag of words, Monte Carlo, and another library-provided similarity) plus global sentiment scoring. Across algorithms, the plugin’s most useful output is the relative ranking—how one note compares to others—rather than the exact numeric values. Controls like sorting, hover previews, and “freeze” help users explore without getting overwhelmed.
How can link prediction help a user decide which notes to connect next?
What’s the difference between similarity and link prediction in Graph Analysis?
Why do HITS results stay the same when switching the focused note?
How does label propagation form communities, and what does changing iterations do?
What does the “freeze” icon accomplish for non-global algorithms?
What extra setup is required to use NLP algorithms, and what do they measure?
Review Questions
- Which structural algorithms in Graph Analysis are global, and how can you tell from the interface?
- When would you prefer similarity over link prediction while curating links in your vault?
- How do tags and regular expressions differ when excluding notes from Graph Analysis results?
Key Points
- 1
Graph Analysis distinguishes structural algorithms (link-structure only) from NLP algorithms (word/content-based), and the best workflow depends on which signal you want.
- 2
Relative rankings across notes are more reliable than exact numeric values; use sorting and hover previews to interpret results.
- 3
Link prediction estimates which notes should be connected next, and icons indicate whether predicted links already exist.
- 4
Similarity algorithms measure neighborhood overlap, helping identify related notes even when no direct link exists.
- 5
HITS centrality reports hub (outgoing links) and authority (incoming links) scores and runs as a global algorithm that doesn’t change with focus.
- 6
Community detection includes label propagation (iterations control community size) and Louvain (local to focus and can vary on refresh).
- 7
Graph Analysis can expand beyond Markdown by including other file types and can exclude notes using tags or regex matched against full file paths.