Grounded theory and line-by-line coding in NVivo
Based on Qualitative Researcher Dr Kriukow's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Grounded theory coding in NVivo should avoid imposing pre-existing thematic or theoretical frameworks on the data.
Briefing
Grounded theory research in NVivo doesn’t require a special, NVivo-specific method so much as it demands a more granular coding discipline: coding line by line at the start so key concepts can emerge from the data rather than from pre-set frameworks. The core idea is to avoid imposing existing thematic or theoretical models on the dataset. Instead, researchers begin “from scratch,” letting patterns and explanations develop out of what participants actually say.
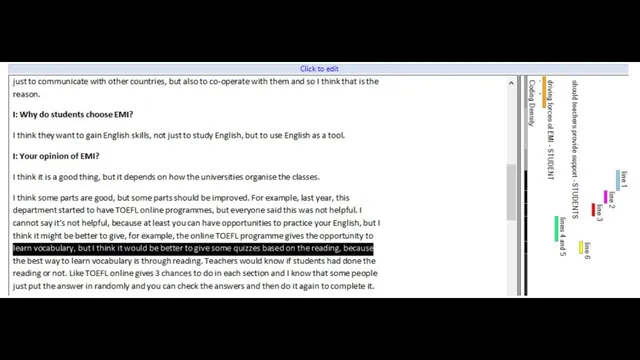
That principle is why line-by-line coding becomes central. Early in a grounded theory project, researchers often code nearly every line as a compact summary of what that line is doing conceptually. The number of initial codes can be large—one example cited from a study of Polish migrant English language identity used 171 line-by-line codes based on only the first three or four interviews. The workflow then shifts: once the same codes start repeating and no genuinely new codes are appearing, researchers can organize, inspect, and merge those detailed codes into broader, more inclusive categories.
The practical payoff is illustrated through a concrete coding comparison. An extract about differences in communicating in Polish versus English initially received a broad code (“being different in Polish and English”). But when the same extract was coded line by line, it split into multiple more specific codes, including “being able to express oneself better in Polish,” “beliefs about other people’s perceptions,” and “differences in being perceived by Polish people and Scottish people.” One of those finer-grained codes—beliefs about other people’s perceptions—later surfaced as a major theme and a core element of the study’s thematic framework and explanation of English language identity. Without the line-by-line approach, that concept would likely have been flattened into the broader “Polish vs English differences” label and missed.
Finally, the transcript addresses how to implement this in NVivo. The mechanics of grounded theory in NVivo are essentially the same as for other qualitative approaches: the difference lies in how detailed the coding is at the beginning and how codes are later merged into more abstract categories. The main technical complication depends on NVivo version. In NVivo 10, the coding interface makes it hard to tell which code corresponds to which specific line, which undermines the purpose of line-by-line coding. NVivo 11 (and likely NVivo 12) improves this by making the line-to-code mapping clearer, with corresponding codes shown alongside lines.
For those still needing extra clarity, the transcript mentions a workaround: using Microsoft Word tables to create a horizontal “code next to each line” guide, then importing and applying those codes in NVivo. The workaround is time-consuming because Word tables aren’t automatically recognized as NVivo codes, but they can help maintain a transparent line-by-line coding trail. Overall, grounded theory in NVivo is straightforward to apply—what matters is the disciplined, detailed coding early on and the careful merging later, not any special NVivo feature.
Cornell Notes
Grounded theory in NVivo hinges on two principles: avoid imposing pre-existing frameworks and begin with highly detailed coding so concepts can surface from the data. Line-by-line coding is typically used early, with each line receiving a short conceptual code; later, researchers inspect repetition and merge many small codes into broader categories. A cited example from a study of Polish migrant English language identity shows how a broad code (“being different in Polish and English”) would have obscured a major theme (“beliefs about other people’s perceptions”) that only became visible through line-by-line coding. NVivo doesn’t change the grounded theory logic, but NVivo version affects how clearly line-to-code links can be seen—NVivo 10 can make this unclear, while NVivo 11 improves it. A Word-table workaround can help but adds time.
Why does grounded theory require researchers to avoid pre-existing frameworks when coding?
What is the purpose of line-by-line coding at the start of a grounded theory project?
How can line-by-line coding change what themes become visible?
Does grounded theory require special NVivo steps beyond coding and merging?
Why does NVivo version matter for line-by-line coding?
What workaround is suggested when NVivo doesn’t make line-to-code mapping clear?
Review Questions
- What two grounded theory principles are highlighted as especially relevant when coding in NVivo, and how do they affect bias?
- Describe a scenario where a broad initial code could hide a major theme, and explain how line-by-line coding prevents that.
- How does the transcript connect NVivo 10 versus NVivo 11 to the feasibility of line-by-line coding?
Key Points
- 1
Grounded theory coding in NVivo should avoid imposing pre-existing thematic or theoretical frameworks on the data.
- 2
Line-by-line coding is typically used early to capture subtle meanings, then reduced later by organizing and merging repeating codes.
- 3
A broad code like “being different in Polish and English” can obscure major themes that only appear when the same extract is split into finer line-level codes.
- 4
NVivo doesn’t change the grounded theory logic; the difference is the level of coding detail early on and the later merging into abstract categories.
- 5
NVivo 10 may make line-to-code mapping unclear, which can undermine line-by-line coding’s purpose.
- 6
NVivo 11 (and likely NVivo 12) improves line-to-code clarity by showing codes corresponding to specific lines.
- 7
A Microsoft Word table workaround can create a clearer horizontal code-by-line guide, but it adds time because Word tables aren’t automatically imported as NVivo codes.