Hamming codes part 2: The one-line implementation
Based on 3Blue1Brown's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Hamming-code parity-check results can be read as the binary index of a single flipped bit, not just as a yes/no error flag.
Briefing
Hamming codes can locate a single flipped bit with an error position that drops out directly from XOR—so the receiver’s core job can shrink to one line of computation. Instead of “binary searching” through candidate error locations using multiple parity checks, the parity results can be read as the error index itself in binary; that same logic can be packaged into a single XOR reduction over the indices of all 1 bits. The payoff is practical: the redundancy grows only logarithmically with block size, making single-error correction efficient even for large blocks.
The mechanism starts with four parity checks for a 16-bit block. Each check corresponds to a specific bit pattern in the binary representation of the position labels 0000 through 1111. For any error at position 7 (binary 0111), the first three parity groups flip while the last does not—so the four parity outcomes, read bottom-to-top, spell out 0111, i.e., the error location. This isn’t a special case: the parity groups are constructed so that every position has a unique binary signature across the checks, meaning the syndrome (the parity-check results) uniquely identifies which single bit flipped.
Why parity bits land in positions that are powers of two (1, 2, 4, 8) becomes clearer once positions are viewed as binary numbers with one “1” bit. Those power-of-two indices have exactly one set bit in their binary label, so each parity bit participates in exactly one parity group. That structure generalizes cleanly: for a block with more positions, each additional binary digit required to label indices contributes another parity check, letting the scheme scale to larger powers of two.
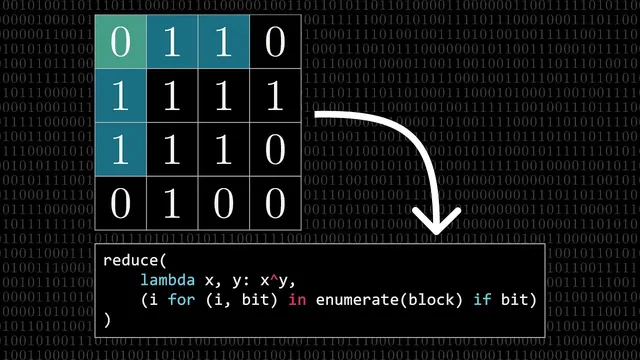
The transcript then reframes the same idea using XOR. XOR of many bit strings is equivalent to adding them mod 2 without carries, so it naturally computes parities across multiple groups at once. Concretely, label each position in binary, select the indices where the received bits are 1, and XOR all those indices together. If the block is “well-prepared” (parity bits chosen so the total XOR is 0), then any single-bit flip changes the set of included indices: a 0→1 adds that index to the XOR sum, while a 1→0 removes it. Because XOR is its own inverse (adding the same index twice cancels), the final XOR result becomes exactly the binary position of the error—or 0 if no error occurred.
A Python sketch illustrates the receiver-side logic: enumerate indices, filter to those where bits are 1, then reduce the list with XOR. The same approach scales beyond 16 bits; the core computation remains an XOR reduction over indices of 1s. Efficiency improves as blocks grow: for 256 bits, only about 3% of space is redundancy, and for extremely large blocks the number of parity bits grows slowly (logarithmically). The tradeoff is error model limits: Hamming codes correct only single-bit errors, and larger blocks face higher odds of multiple flips. Burst errors also motivate interlacing blocks, while more advanced codes like Reed-Solomon handle bursts better.
Finally, the transcript situates the elegance historically. Hamming’s discovery is portrayed as non-obvious—he experimented widely before landing on the parity-check structure that encodes error locations. The broader context links Hamming’s work to Shannon’s information theory, emphasizing that efficient error correction and the “bits-first” worldview were still coalescing in the mid-20th century. The result feels simple in hindsight, but the underlying design space and conceptual leap were anything but.
Cornell Notes
Hamming codes can identify the location of a single flipped bit by turning parity-check outcomes into the error index written in binary. For a 16-bit block with four parity checks, each check corresponds to one binary digit of the position labels 0000–1111, so the syndrome uniquely spells out the error location (e.g., 0111 for position 7). The same logic can be implemented more directly in software: XOR together the indices of all positions whose received bits are 1. If the block was correctly prepared, the total XOR is 0; a single-bit flip changes the XOR to the exact error position, or leaves it 0 when no error occurred. This yields logarithmic redundancy growth with block size, but performance depends on the assumption of at most one bit error per block.
How do four parity checks for a 16-bit block end up encoding an error position in binary?
Why do parity bits sit at positions like 1, 2, 4, and 8?
How does XOR replace multiple parity checks with a single operation?
Why does the XOR of indices of 1 bits equal the error location after a single-bit flip?
What scaling behavior makes Hamming codes efficient, and what breaks that efficiency?
How does the transcript connect this to broader coding and information theory?
Review Questions
- In a 16-bit Hamming-code setup with four parity checks, what binary relationship between an index label and the parity groups guarantees that the syndrome uniquely identifies a single-bit error?
- Explain why XOR of the indices of 1 bits yields 0 for a correctly prepared block and becomes the error position after a single-bit flip.
- What assumptions about error frequency and error patterns (single-bit vs burst/multiple-bit) determine when Hamming codes are practical?
Key Points
- 1
Hamming-code parity-check results can be read as the binary index of a single flipped bit, not just as a yes/no error flag.
- 2
Parity groups are constructed by mapping each position to a binary label and assigning each parity check to one binary digit of that label.
- 3
Parity bits naturally belong at power-of-two positions because those indices have exactly one set bit in their binary representation, making each parity bit touch only one parity group.
- 4
XOR can compute the same syndrome in one step: XOR together the indices of all positions whose received bits are 1.
- 5
A correctly prepared block yields XOR=0; a single-bit flip changes the XOR to the exact error position, while no flip leaves it at 0.
- 6
Redundancy grows logarithmically with block size, improving efficiency for larger blocks, but the scheme fails to correct multiple-bit errors.
- 7
Burst errors often require interlacing or switching to stronger codes like Reed-Solomon for better burst resilience.