How might LLMs store facts | Deep Learning Chapter 7
Based on 3Blue1Brown's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Facts can be represented as directions in a high-dimensional embedding space, and transformer MLP blocks can transform those directions into new feature directions.
Briefing
Large language models don’t just “know” facts in a vague sense—those facts can be traced to specific internal computations, especially inside the multilayer perceptron (MLP) parts of transformer networks. A concrete toy example uses the prompt “Michael Jordan plays the sport of blank” to show how an MLP block could, in principle, turn a representation of “Michael Jordan” into an added direction corresponding to “basketball.” Even though a full mechanistic map of real-world fact storage remains unsolved, the evidence discussed points to a broad pattern: the most useful capacity for storing and transforming factual associations appears concentrated in the MLP sub-networks rather than the attention mechanism alone.
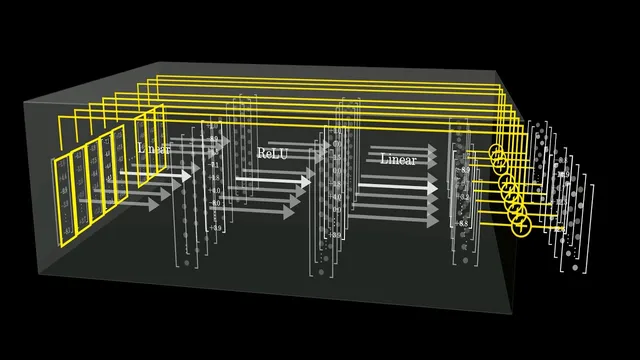
The explanation starts with how transformer vectors encode meaning in a high-dimensional space. Different directions in that space can represent different features. Under simplifying assumptions, one direction corresponds to the first name “Michael,” another nearly perpendicular direction corresponds to the last name “Jordan,” and a third direction corresponds to “basketball.” If an internal vector aligns with both “Michael” and “Jordan,” then the MLP’s computations can be arranged so that the “basketball” direction gets injected into the output.
Inside an MLP block, each token’s vector is processed independently in parallel. The core computation is two matrix multiplications with biases and a nonlinearity in between. First comes an “up projection” matrix: it linearly mixes the input vector into a larger hidden space. Then a ReLU activation clips negative values to zero, turning a fuzzy linear score into a more gate-like signal. With a carefully chosen bias, a hidden neuron can behave like an AND gate: it activates only when the input vector simultaneously indicates “Michael” and “Jordan,” while other partial matches (like “Michael” with a different last name) fail to activate it. Finally, a “down projection” matrix maps the activated hidden units back into the original embedding dimension. In the toy setup, one particular column in this down-projection matrix is aligned with the “basketball” direction, so activating the “Michael Jordan” neuron causes the output vector to gain the “basketball” component. The block then adds this result back to the residual stream.
The transcript also grounds the toy story in scale. For GPT-3, the up and down projection matrices each contribute roughly 1.2 billion parameters together, and 96 separate MLPs bring the total MLP parameter count to about 116 billion—around two-thirds of the model’s 175 billion parameters. Normalization-related parameters exist too, but they’re described as a small fraction.
A key twist comes from interpretability research: individual neurons may not correspond to single clean concepts like “Michael Jordan.” Instead, a “superposition” hypothesis suggests that many features share the same neurons by using nearly orthogonal directions in high-dimensional space. In high dimensions, it becomes possible to pack exponentially more nearly perpendicular feature directions than the raw dimensionality would suggest, which helps explain why models can scale well while remaining hard to interpret. In that view, features are distributed across combinations of neurons rather than appearing as a single, obvious activation; tools like sparse autoencoders are mentioned as a way to tease out these hidden features. The next major step promised is the training process—backpropagation, language-model loss functions, reinforcement learning with human feedback, and scaling laws.
Cornell Notes
The transcript explains how factual associations could be stored and retrieved inside transformer MLP blocks. Using a toy example for “Michael Jordan plays basketball,” it assumes specific directions in a high-dimensional embedding space represent “Michael,” “Jordan,” and “basketball.” An MLP block then uses an up-projection matrix, a ReLU nonlinearity (with a bias tuned to act like an AND gate), and a down-projection matrix so that when the internal representation matches “Michael Jordan,” the output gains the “basketball” direction. While this is a clean mathematical construction, real models likely use superposition: many features share neurons via nearly orthogonal directions, making individual neurons less interpretable. This helps reconcile strong performance with interpretability challenges and motivates methods like sparse autoencoders.
How does the toy “Michael Jordan → basketball” example map facts into transformer vectors?
What computation does an MLP block perform, and why does it matter for storing associations?
How does ReLU enable something like an AND gate in the toy construction?
Why might real neurons fail to represent single clean facts like “Michael Jordan”?
What role do high-dimensional geometry results play in superposition?
How much of GPT-3’s parameter budget sits in MLPs, and why is that relevant?
Review Questions
- In the toy model, what specific sequence of operations in an MLP makes “Michael Jordan” activate a hidden unit that then adds the “basketball” direction?
- What is the difference between exact orthogonality and near-orthogonality in the superposition argument, and how does that change the number of features that can be represented?
- Why does the transcript suggest that interpretability methods like sparse autoencoders are needed if features are in superposition?
Key Points
- 1
Facts can be represented as directions in a high-dimensional embedding space, and transformer MLP blocks can transform those directions into new feature directions.
- 2
An MLP block’s core computation is an up projection (matrix multiply + bias), a ReLU (or similar) nonlinearity, then a down projection (matrix multiply + bias) followed by a residual addition.
- 3
With suitable biases and assumptions, ReLU can turn linear “partial match” signals into gate-like behavior that resembles an AND condition for a conjunction such as “Michael Jordan.”
- 4
Parameter capacity is heavily concentrated in MLPs: in GPT-3, MLPs account for about 116B of 175B parameters (around two-thirds).
- 5
A superposition hypothesis suggests neurons rarely correspond to single clean concepts; instead, many features overlap in neuron activations using nearly orthogonal directions.
- 6
High-dimensional geometry (including ideas related to the Johnson–Lindenstrauss lemma) helps explain why near-orthogonal feature directions can be packed far beyond the raw dimensionality.
- 7
If features are superimposed, interpretability requires tools that can disentangle distributed representations, such as sparse autoencoders.