How to Analyze Tables In Large Financial Reports Using GPT-4 (w/Jerry Liu, LlamaIndex)
Based on Chat with data's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Naive chunk-and-embed retrieval often fails on embedded tables because raw table text is dense and number-heavy, producing poor top-k matches.
Briefing
Advanced RAG for financial filings hinges on treating embedded tables as first-class, queryable objects—then retrieving them indirectly through summaries and a recursive lookup—rather than embedding raw table text like ordinary chunks. In large documents such as SEC 10-Ks (and even Wikipedia’s “world billionaires” tables), naive chunk-and-embed retrieval often fails because table contents are dense, number-heavy, and semantically hard to match. The result is either missed tables or answers that don’t correspond to the correct figures.
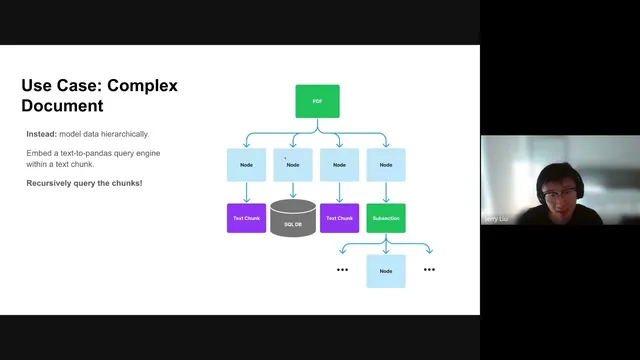
The core fix is a hierarchical indexing strategy. Text sections and extracted tables are mapped into separate “nodes”: text trunks become nodes containing the text itself, while table nodes store an LLM-generated summary plus a reference (via an ID) to a structured query engine for the underlying table. At query time, a top-level vector retriever selects the most relevant nodes based on semantic similarity. Then recursive retrieval kicks in: if a retrieved node is merely text, standard RAG continues; if it’s a table summary node, the system follows the reference and runs a targeted query against the table (for example, via a pandas-based query engine). This indirect reference approach avoids the poor retrieval behavior of embedding entire tables as plain text, while still enabling precise extraction of numbers.
The demo starts with Wikipedia’s billionaires page converted to PDF and parsed with Camelot, which extracts clean tables into data frames. For each table, the system builds a pandas query engine and pairs it with a summary node. When asked, “How many billionaires were there in 2009?” the recursive retriever pulls the correct table summary node, then executes the corresponding pandas operation to return the exact value (793). A baseline RAG pipeline that simply chunks and embeds the flattened document text fails on the same question, returning “not possible to determine” and even hallucinating by pulling the wrong year’s table content.
A second example uses an SEC filing in HTML form (a 10-K) processed with Unstructured to partition content into a document hierarchy. Tables are extracted into nodes, and each table node is again represented by an LLM summary rather than the full raw table. Even when the extracted tables are messy or partially missing formatting, the summary-based retrieval helps the system locate the right table node; then recursive retrieval queries the underlying table to answer questions like “What was the revenue in 2020?” The baseline approach again struggles, even for straightforward numeric questions.
Beyond the demos, the discussion frames production tradeoffs: table parsing quality and document-tree construction strongly affect downstream accuracy; summary quality matters because retrieval depends on it; and preprocessing (parsing plus LLM summarization across many tables) can add latency, though the actual retrieval step is typically fast. The architecture is also flexible about persistence—table data can live in a document store, SQL database, or vector database—because recursive retrieval follows references rather than assuming a single storage model. Finally, there’s an open question about whether multimodal table parsing (e.g., screenshot-to-description with GPT-4V) can improve summaries versus text-based extraction, especially when tables are not cleanly parseable.
Cornell Notes
The approach for querying large financial documents with embedded tables replaces “embed the whole table” with a hierarchical, recursive RAG design. Tables are extracted into structured data frames, but the index stores a compact LLM summary plus a reference to a table-specific query engine (e.g., pandas). A vector retriever first selects relevant nodes using those summaries; recursive retrieval then follows table references and runs precise queries to pull exact numbers. This avoids naive RAG failures where flattened, number-dense table text leads to wrong retrieval or hallucinated year/value matches. The method works for both clean PDF tables (Camelot) and messier filings (Unstructured), and it can be persisted in different backends because references drive the lookup.
Why does naive RAG struggle with embedded tables in financial documents?
How does recursive retrieval improve table question answering?
What does a “table node” contain in the LlamaIndex-style architecture described?
How were tables extracted in the two main demos, and why does it matter?
What tradeoffs affect latency, cost, and accuracy in this workflow?
Does the architecture require storing tables in a specific database type?
Review Questions
- In what way does embedding a table “as-is” differ from embedding a table summary plus a reference to a query engine, and how does that change retrieval outcomes?
- Describe the sequence of steps from user question to final answer in recursive retrieval for a table-backed node.
- What factors most strongly determine whether the system retrieves the correct table node in messy filings?
Key Points
- 1
Naive chunk-and-embed retrieval often fails on embedded tables because raw table text is dense and number-heavy, producing poor top-k matches.
- 2
Index tables as summaries plus references to structured query engines, rather than embedding entire tables as plain text.
- 3
Use a top-level vector retriever to select relevant nodes, then apply recursive retrieval to follow table references and run precise table queries.
- 4
Table parsing quality (Camelot for clean PDFs, Unstructured for messier filings) directly impacts correctness of numeric answers.
- 5
LLM-generated table summaries must be descriptive enough to be retrievable; weak summaries reduce table selection accuracy.
- 6
Preprocessing can be slow because it includes parsing and LLM summarization across many tables, while retrieval is typically faster once the index exists.
- 7
Recursive retrieval is storage-agnostic: referenced tables can live in document stores, SQL databases, or vector databases as long as they can be queried.