How to Integrate RAG - Retrieval Augmented Generation into a LLM? (Practical Demo)
Based on AI Researcher's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
RAG answers questions by retrieving relevant document chunks and feeding them to the LLM as grounded context.
Briefing
Retrieval-Augmented Generation (RAG) is presented as a practical way to make a language model answer questions using external, user-provided sources instead of relying only on what it already “knows.” The core workflow is straightforward: split documents into chunks, embed both the chunks and the user’s question into the same vector space, retrieve the most similar chunks via cosine similarity, then feed the retrieved context plus a system instruction into the LLM to generate a grounded response. The practical payoff is accuracy—when the retrieved context actually contains the relevant facts, the model’s answer shifts from generic or incorrect output to something that matches the source material.
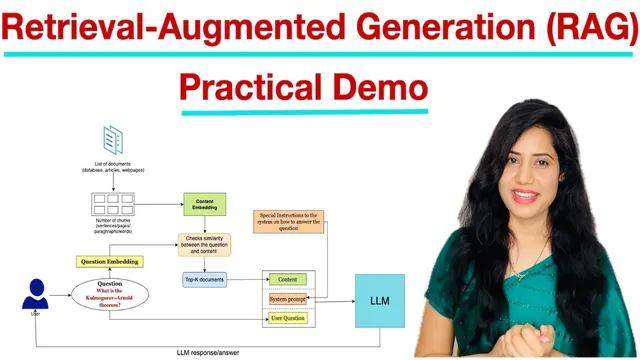
The pipeline begins when a user asks a question to an LLM. In parallel, the system takes a collection of documents—examples include Word files, database articles, or web pages—and converts them into embeddings. Because raw documents are too large to compare directly, the text is divided into smaller chunks (sentences, paragraphs, or lines). Each chunk is transformed from text into a numeric vector using an embedding model; this “content embedding” captures semantic meaning. The user question is embedded as well, producing a “question embedding.”
With both embeddings ready, the system runs a similarity check between the question vector and each content chunk vector. Cosine similarity is used to rank chunks by relevance, and the top-K results are selected (the demo uses K=4). This retrieval step matters because it narrows the LLM’s input to only the most relevant evidence, reducing the chance of hallucination or off-target answers.
After retrieval, the system constructs the final prompt. A system instruction is included to steer the LLM toward concise, accurate responses (the demo uses an instruction like “provide a concise and accurate response”). The retrieved chunks are concatenated into a context block, and the model receives the system prompt, the context, and the original user question. The LLM then generates a one-sentence answer grounded in the retrieved material.
The implementation demo contrasts two scenarios using the same question: first, generating an answer with GPT-2 alone (without RAG), and then generating an answer with GPT-2 plus RAG. Without retrieval, the output is shown as vague and not really aligned with the question about the “Cologarando theorem” (as spelled in the transcript). With RAG, the system loads a relevant web page, parses it with BeautifulSoup, chunks the extracted text, embeds each chunk using all-MiniLM-L6-v2 from Hugging Face, retrieves the top four most similar lines using cosine similarity, and feeds those lines into the LLM. The resulting response is described as much more relevant to the theorem question.
The demo also walks through practical setup: importing libraries for web scraping and embeddings (pandas, BeautifulSoup, sentence-transformers), logging into Hugging Face to access models, and using Hugging Face to load both the GPT-2 text generation model and the embedding model. A GitHub link is referenced for the code, and the workflow is summarized as load documents → index (embed) → retrieve (similarity search) → generate (LLM with retrieved context).
Cornell Notes
RAG makes an LLM answer questions using external documents by retrieving relevant text chunks and supplying them as context. The workflow embeds document chunks and the user question into the same vector space, then ranks chunks by cosine similarity and selects the top K (the demo uses K=4). Those retrieved chunks become the context for the LLM, along with a system instruction to produce a concise, accurate answer. In the demo, GPT-2 alone gives an off-target response to a theorem question, while GPT-2 with RAG produces a more relevant answer because it is grounded in retrieved lines from a scraped web page. This approach reduces hallucinations and improves factual alignment when the needed information exists in the provided sources.
What are the main stages of a RAG pipeline, and what does each stage accomplish?
Why split documents into chunks before embedding?
How does the demo retrieve relevant evidence for the question?
What role do system instructions play during response generation?
What changes between “LLM without RAG” and “LLM with RAG” in the demo?
Which tools and models are used for the practical implementation?
Review Questions
- If you increase K in top-K retrieval, what kinds of effects might you expect on answer relevance and potential noise?
- Why must the question and document chunks be embedded using the same embedding model (or at least a compatible embedding space)?
- In the demo, what evidence is used to justify that retrieval worked correctly before generating the final answer?
Key Points
- 1
RAG answers questions by retrieving relevant document chunks and feeding them to the LLM as grounded context.
- 2
Documents should be split into smaller chunks (sentences/paragraphs/lines) before embedding to enable targeted retrieval.
- 3
Both document chunks and the user question must be embedded into the same vector space so cosine similarity can rank relevance.
- 4
Top-K retrieval (e.g., K=4) selects the most similar chunks to form the context for generation.
- 5
A system prompt can enforce response constraints like conciseness and accuracy while the retrieved context supplies the facts.
- 6
The practical demo contrasts GPT-2 alone (often off-target) with GPT-2 plus RAG (more relevant) by adding retrieval from a scraped web page.