I was wrong about AI costs (they keep going up)
Based on Theo - t3․gg's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Benchmark costs can diverge wildly from published token rates when reasoning inflates output token counts.
Briefing
AI costs are rising in practice because “reasoning” is driving output token counts into the stratosphere—so cheaper per-token pricing gets overwhelmed by far more tokens being generated. That mismatch helps explain why benchmark runs can cost orders of magnitude more on certain frontier models even when their published token rates look lower, and it reshapes how AI products can price compute without collapsing margins.
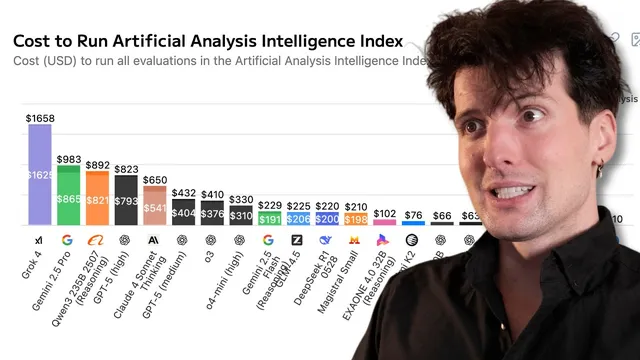
The cost charts that once suggested a simple hierarchy—models with lower token prices should be cheaper to run—don’t match real benchmark bills. In one repeated skate-trick naming benchmark (“skatebench”), Grok 4’s token pricing looked like it should be competitive, but the run cost landed dramatically higher than alternatives. The core culprit wasn’t input cost; it was output volume created by reasoning behavior. A non-reasoning model produced a short answer in single-digit output tokens, while a reasoning-enabled Claude variant generated hundreds of output tokens for the same task. Grok 4 went further: it “thinks” for a long time, doesn’t provide explicit reasoning tokens, and still burns hundreds of tokens worth of compute. The result is a benchmark where Grok 4 can cost more than 2x every other model on the chart, and in some comparisons the total cost difference reaches 20–30x for the same benchmark inputs.
This token explosion also breaks the logic behind “inference will get 10x cheaper, so margins will eventually recover.” Even if per-token rates fall, product usage patterns shift. As models improve, users ask for longer, more agent-like workflows—planning, reading, rewriting, and iterative refinement—so the number of tokens consumed per request grows faster than pricing drops. The transcript describes a shift from short chat replies to “deep research” style runs that can take minutes of planning and large amounts of generated text. The practical implication: a $20/month subscription can’t reliably fund a user who runs frequent long agent tasks, especially once asynchronous fleets of agents can operate continuously.
The pricing fallout shows up in real-world subscription experiments. Claude Code’s “unlimited” tier was rolled back after token consumption surged beyond what flat-rate pricing could sustain. The transcript frames this as a structural problem: there may be no flat subscription price that works when reasoning and agent behavior decouple token consumption from human time. Unlimited plans become a “prisoner’s dilemma,” where one company’s subsidized compute attracts power users and forces others into unsustainable unit economics.
The discussion then pivots from model economics to business strategy. If usage-based pricing is the only sustainable path, consumer users often resist metered billing, preferring the predictability of flat plans. That pushes companies toward three escape routes: (1) usage pricing from day one without subsidies, (2) building high-switching-cost enterprise contracts where churn is hard, or (3) vertical integration—bundling inference with hosting, deployment, monitoring, and other layers so the company captures value even if inference becomes cheap. The transcript argues that companies sticking to flat-rate growth “at all costs” are likely headed for expensive failures, because the goalposts keep moving as models get better and users demand more compute per request.
Cornell Notes
Frontier AI models can be far more expensive to run than their published token prices suggest because reasoning behavior massively increases output token counts. In a skate-trick benchmark, non-reasoning models returned answers in ~single-digit output tokens, while reasoning models generated hundreds of tokens for the same task; Grok 4’s “thinking” behavior drove even higher compute burn despite not exposing explicit reasoning tokens. This output-token explosion means per-token cost reductions don’t translate into stable margins, especially as products shift toward agent-like workflows that consume far more tokens per request. Flat-rate subscriptions struggle because token consumption can decouple from human time, enabling long asynchronous runs that break unit economics. Sustainable models increasingly require usage-based pricing, enterprise switching-cost strategies, or vertical integration to capture value beyond inference.
Why do published token prices fail to predict real benchmark costs?
How does reasoning change token counts in practice?
What does this imply for the “models get 10x cheaper, margins will recover” strategy?
Why do unlimited or flat-rate AI subscriptions break under agent workloads?
What business strategies are offered as alternatives to pure usage-based pricing?
Why does the transcript claim flat-rate growth can become a “race to the bottom”?
Review Questions
- In the skatebench example, what specific mechanism makes reasoning models cost more than non-reasoning models even when input token prices are similar?
- How does decoupling token consumption from human time undermine flat-rate subscription economics?
- Which of the three proposed business strategies (usage pricing, enterprise switching costs, vertical integration) best addresses the transcript’s “token short squeeze,” and why?
Key Points
- 1
Benchmark costs can diverge wildly from published token rates when reasoning inflates output token counts.
- 2
Output tokens are typically more expensive than input tokens, so reasoning-heavy models can multiply total cost even on identical inputs.
- 3
Per-token price drops don’t guarantee margin recovery if product usage shifts toward longer agent workflows that generate far more tokens per request.
- 4
Unlimited or flat-rate subscriptions fail when agent behavior enables long asynchronous runs that break predictable unit economics.
- 5
Sustainable AI pricing often requires usage-based billing, enterprise switching-cost design, or vertical integration to capture value beyond inference.
- 6
Power-user migration and subsidized unlimited plans create a prisoner’s dilemma that can push competitors toward unsustainable losses.