It's Really Just That Bad
Based on The PrimeTime's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Don’t trust language benchmark rankings without verifying that implementations compute the same problem on the same inputs.
Briefing
A widely shared “language benchmark” ranking that put Fortran far ahead of C (and other languages) collapses under basic verification: the Fortran implementation is effectively not computing the full Levenshtein distance workload the benchmark claims to measure. The mismatch isn’t subtle. When the benchmark is stress-tested with additional checks, the Fortran program reports correct-looking minimum distances while failing to produce correct maximum distances—then the root cause is traced to input “clipping” that shortens the strings being compared. That clipping dramatically reduces the amount of work in an O(n²) pairwise string comparison, letting Fortran appear faster without actually doing the same computation.
The discussion starts with the Levenshtein distance benchmark itself—an algorithm that compares two strings by counting the minimum number of edits (insertions, deletions, substitutions) needed to transform one into the other. The benchmark’s outer structure forces a huge amount of work: it loops over all pairs of strings, yielding an n² comparison count, and each comparison itself loops over characters, making the hottest path effectively an “n to the fourth” style workload. That’s why performance differences should be meaningful only if every language implementation performs the same algorithm on the same inputs.
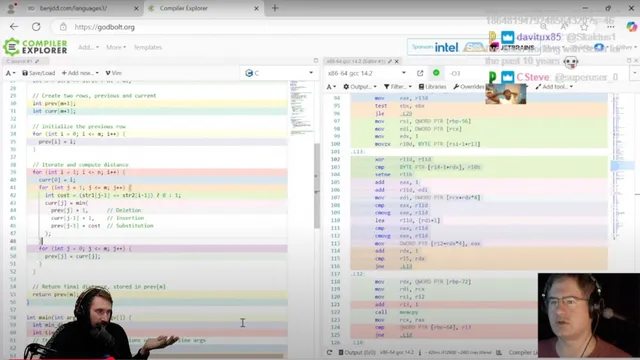
Yet the Fortran-vs-C speed gap looks suspicious even at the assembly level. After compiling optimized C and Fortran versions, the generated inner-loop code is largely the same: both inline the same kind of min-of-three logic and use branch-free conditional moves rather than branches. The only notable difference is minor instruction scheduling and an extra loop unroll in the Fortran build—but the unroll doesn’t explain the large timing advantage. A forced unroll pragma doesn’t change performance either, undermining the “Fortran is inherently faster” narrative.
The real break comes when the benchmark is run with the exact input it uses. The benchmark passes the strings via command-line arguments, which already adds a questionable confounder (command-line parsing time and behavior), but the more serious issue is correctness. The Fortran code appears to match the benchmark’s expected minimum distance under the benchmark’s own reporting, which can mask errors because matching only the closest pair doesn’t guarantee the full distance matrix is computed correctly.
When the analysis expands to compute a maximum distance as well, the results diverge: the Fortran version finds a maximum that doesn’t align with the C version. That discrepancy points to a logic issue rather than a compiler optimization. Inspecting Fortran-specific behavior reveals the program is using the “Klippenstein algorithm” (not the straightforward Levenshtein computation implied by the benchmark), clipping the input strings to a smaller effective length. In an all-pairs distance workload, reducing string length reduces the work per comparison, so the benchmark’s timing becomes a measure of an altered problem size—not a fair comparison of language speed on the same algorithm.
Even after correcting the behavior to use the full strings, the ordering flips: C becomes faster than Fortran. The conclusion is blunt: the benchmark is methodologically unreliable because it lacks validation of correctness and equivalence across implementations, and it mixes in performance-relevant implementation details (like dynamic allocation patterns and input handling) that aren’t controlled. The broader takeaway is that microbenchmarks posted as rankings—especially when correctness checks are missing—can spread misinformation faster than they can be audited, turning language performance debates into “benchmarking bugs” rather than engineering insight.
Cornell Notes
The Levenshtein distance benchmark that ranked Fortran far above C fails a basic equivalence test. Assembly inspection shows the inner-loop logic for C and Fortran is largely the same, so the huge speed gap can’t be explained by compiler codegen alone. When the benchmark is validated more thoroughly (e.g., checking maximum distances, not just the minimum), the Fortran result is inconsistent with C. The discrepancy traces to the Fortran implementation using the Klippenstein algorithm, which clips input strings—reducing the effective work in an all-pairs O(n²) workload. Once the full strings are used, the performance ordering flips, showing the original ranking measured a smaller problem, not true language speed.
Why does the Levenshtein “all pairs” benchmark create such a heavy performance hotspot?
What did assembly-level inspection reveal about the C vs Fortran implementations?
How can a benchmark appear correct while still being wrong?
What specific bug/behavior undermined the Fortran speed advantage?
What happens to the performance ranking after using the full strings?
Why is command-line input handling a methodological red flag in this benchmark?
Review Questions
- What evidence suggests the Fortran speedup wasn’t due to fundamentally different inner-loop codegen?
- How does checking only a benchmark’s reported minimum distance risk missing correctness problems?
- Why does clipping string lengths disproportionately affect runtime in an all-pairs Levenshtein workload?
Key Points
- 1
Don’t trust language benchmark rankings without verifying that implementations compute the same problem on the same inputs.
- 2
Assembly inspection can quickly rule out “mystery” speedups when inner-loop logic and optimizations (like inlining and conditional moves) are effectively equivalent.
- 3
A benchmark that reports only a single metric (e.g., minimum distance) can mask widespread correctness errors across the rest of the distance matrix.
- 4
Input clipping or algorithm substitution (e.g., using the Klippenstein algorithm) can reduce effective work and produce misleading performance results.
- 5
Benchmark methodology matters: command-line argument parsing can introduce confounds unrelated to the algorithm under test.
- 6
If performance ordering flips after correcting equivalence (e.g., using full strings), the original ranking likely measured a smaller problem, not true language speed.
- 7
Microbenchmarks posted as rankings without correctness validation can spread misinformation and force maintainers into defensive, low-signal debates.