Lab 02: PyTorch Lightning and Convolutional NNs (FSDL 2022)
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
PyTorch Lightning reduces the need to hand-write and maintain training loops by separating model logic, data loading, orchestration, and optional features like checkpointing.
Briefing
PyTorch Lightning is presented as the practical fix for the “sharp edges” of hand-rolling PyTorch training loops—especially when training needs to scale to GPUs, data loaders, validation/testing, checkpointing, and reusable boilerplate. Instead of writing one-off loops, Lightning layers a structured training stack on top of PyTorch: Lightning Modules wrap torch.nn models, Lightning Data Modules organize datasets and data loaders, the Lightning Trainer orchestrates the training/validation/testing loops, and callbacks add features like model checkpointing without rewriting core logic. That structure matters because it reduces the friction and hidden complexity that show up once projects move beyond simple CPU experiments into real training workflows where reuse, flexibility, and maintainability become non-negotiable.
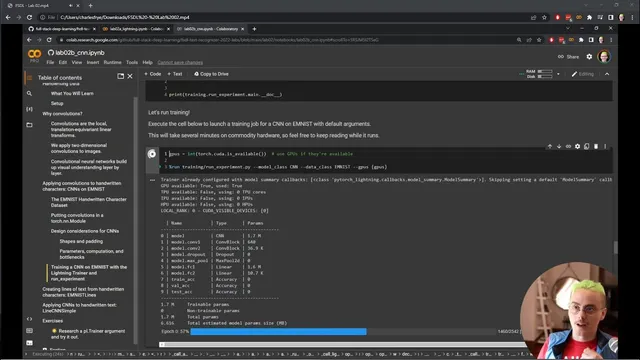
The lab sequence then ties those Lightning components directly into a growing “text recognizer” code base aimed at training and deploying a text recognition system. A new lit_models library holds the PyTorch Lightning modules, while a separate training library adds the machinery needed to run experiments. Central to the workflow is a run experiment.py script that can be executed from a notebook and also imported as a module for interactive inspection. In the convolutional neural network lab (lab2b), the notebook runs training using available GPUs, prints hardware and logging information, and reports a model summary including the number of trainable parameters and the layer structure. Training progress is tracked with an epoch-level progress bar, followed by validation and then testing, with metrics reported across train/validation/test.
After training, the lab emphasizes two operational habits: first, reloading models from checkpoints to continue experimentation, and second, keeping models in an interactive loop rather than staring only at charts. By sending different inputs through the model, the notebook surfaces a key failure mode that metrics alone can hide: single-character ambiguity. The model may correctly guess “zero,” but the same visual pattern could also represent a capital “O,” a lowercase “o,” or even a slanted “d.” These confusions imply that character recognition at a single-character level is likely the wrong target. Real text recognition needs context—what surrounds a character determines whether it’s a zero or an O—so the lab frames ambiguity as evidence that the modeling approach must shift from isolated characters toward sequences.
To address the next step without expensive new data collection, the lab uses data synthesis to bootstrap line-level handwriting training. Although the available dataset contains individual characters, the notebook constructs synthetic handwritten text lines by concatenating characters into sequences using the Brown Corpus sentences as a source of text. The resulting “ransom-note” style lines aren’t perfect, but they are close enough to real-world structure to support code development, reveal practical issues early, and enable training improvements by mixing synthetic and real data. The overall takeaway is a workflow: use Lightning to standardize training, validate models through interactive testing, diagnose dataset-driven ambiguity, and bootstrap sequence modeling with synthetic data until real line-level data is collected.
Cornell Notes
PyTorch Lightning is introduced as a structured training framework that replaces brittle, hand-written PyTorch training loops. Lightning Modules wrap torch.nn models, Lightning Data Modules manage datasets and data loaders, the Lightning Trainer runs training/validation/testing loops, and callbacks handle features like checkpointing. In the CNN lab, training is run via a run experiment.py script that uses GPUs when available, reports model summaries and metrics, saves checkpoints, and supports reloading for interactive experimentation. Interactive testing reveals a major issue: single-character predictions are ambiguous (e.g., “0” vs “O” vs “o” vs “d”), suggesting that context is required for real text recognition. To move toward line-level recognition without new data collection, the lab synthesizes handwritten text lines by concatenating characters into sequences using the Brown Corpus.
Why does the lab treat hand-written PyTorch training loops as a problem worth solving with a framework?
How do Lightning’s core components map to the training workflow used in the labs?
What does the CNN lab’s training run report, and what does it imply about the experiment lifecycle?
What specific failure mode emerges from interactive model testing, and why can metrics miss it?
How does the lab propose moving from character-level data to line-level text without collecting new data immediately?
Review Questions
- What roles do Lightning Modules, Lightning Data Modules, the Lightning Trainer, and callbacks play in reducing training boilerplate?
- Why does single-character ambiguity push the system toward sequence- or context-based recognition rather than isolated classification?
- What is the purpose of synthesizing line-level handwritten text from the Brown Corpus when only character images are available?
Key Points
- 1
PyTorch Lightning reduces the need to hand-write and maintain training loops by separating model logic, data loading, orchestration, and optional features like checkpointing.
- 2
Lightning Modules wrap torch.nn models, while Lightning Data Modules standardize how datasets and data loaders are provided to training.
- 3
The Lightning Trainer coordinates training, validation, and testing loops, producing a consistent experiment lifecycle.
- 4
Interactive checkpoint reloading and input probing help catch dataset-driven failure modes that aggregate metrics can hide.
- 5
Single-character recognition can fail when visually similar classes (e.g., “0” vs “O” vs “o” vs “d”) require surrounding context to disambiguate.
- 6
When line-level data is missing, synthetic data generation can bootstrap development by concatenating character images into line sequences.
- 7
Using the Brown Corpus as a text source enables realistic-enough synthetic handwriting lines to support early modeling and data-handling experiments.