Lab 05: Troubleshooting & Testing (FSDL 2022)
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Use pre-commit to run formatting and linting hooks automatically on every git commit, with isolated tool environments to avoid dependency conflicts.
Briefing
Testing and performance troubleshooting for deep learning systems hinge on two disciplines: automated quality gates for code and data, and a practical workflow for finding bottlenecks inside the training loop. The lab’s central message is that reliable ML work starts long before model accuracy is measured—by enforcing consistent Python/shell hygiene, structuring tests so failures are loud and discoverable, and then using profiling traces to pinpoint why training is slow.
On the code-quality side, the lab focuses on bundling linting and style checks into a single automated command via pre-commit. That approach matters because it isolates tool dependencies in separate environments, avoiding conflicts between a developer’s ML setup and the expectations of linters/formatters. pre-commit runs on every git commit, producing a clear pass/fail report across hooks such as YAML formatting checks, secret-leak detection, and Python tooling like black (formatting) and flake8 (linting with extensions). It also emphasizes that strict enforcement can become counterproductive unless developers have an “escape valve”: targeted ignores (for example, temporarily disabling flake8 type-annotation checks) let teams ship while planning follow-up improvements.
Shell scripts get special attention because they’re a frequent source of subtle bugs—especially when file names include spaces/newlines or when Bash array/variable behavior surprises engineers. The lab recommends shellcheck and shows how to integrate it through pre-commit so it runs automatically without disrupting editing. It also points to “strict mode” ideas from the Bash community: configure scripts so failures terminate the script instead of failing silently under a login shell. The broader testing philosophy is that ML failures are often silent by default, so correctness checks must be engineered to surface problems early.
For correctness testing, the lab moves from quick assert-based checks to structured tests discoverable by tooling. It uses pytest conventions (test_ prefixed functions/classes) and highlights coverage reporting through codecov, including the workflow of keeping tests near implementations during rapid iteration but migrating them into a dedicated tests/ folder for maintainability. It also recommends testing docstrings with doctest so examples in documentation remain executable and less prone to rot.
Training-specific testing centers on memorization tests—overfitting a tiny dataset (often a single batch per epoch) to confirm the training pipeline can learn at all. Using PyTorch Lightning, the lab describes running experiments with an overfit-batches setting and leveraging fast dev run-style flags to keep tests short enough for practical CI. Because GPU access in CI is expensive or unavailable, the lab proposes a budget-based ladder: vary epochs and expected loss thresholds to create memorization tests ranging from minutes on commodity GPUs to longer runs on high-end hardware.
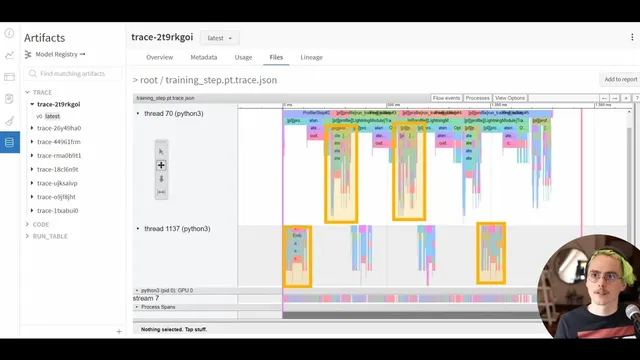
Finally, performance troubleshooting is treated as a trace-reading problem, not a guesswork exercise. The lab profiles a single epoch with PyTorch/PyTorch Lightning tooling, then inspects results in Weights & Biases (and TensorBoard integration). The key metric is GPU utilization—aiming for ~90% or higher—and the trace viewer is used to connect high-level operations (forward pass, backward pass, optimizer step, data loading) to low-level CPU/GPU events like host-to-device memory copies and GPU kernel launches. When GPU streams show long gray idle gaps or frequent synchronization points between CPU and GPU, the bottleneck is likely data loading, synchronization overhead, or host-side scheduling. The lab’s practical guidance includes focusing first on forward-pass optimization (since it shapes the computation graph) and increasing batch size within GPU memory limits to reduce Python overhead relative to GPU compute.
In the end, the lab frames speed and reliability as complementary: automated checks prevent regressions, memorization tests validate learning, and trace-based profiling turns “it’s slow” into a concrete list of bottlenecks to fix—or a decision to scale hardware when code-level changes would be brittle or marginal.
Cornell Notes
The lab lays out a workflow for making ML systems both trustworthy and fast: enforce automated linting/formatting with pre-commit, write structured tests with pytest (plus coverage via codecov and docstring checks via doctest), and validate training with memorization tests that intentionally overfit a tiny dataset. For performance, it uses PyTorch/PyTorch Lightning profiling and trace visualization in Weights & Biases to measure GPU utilization and locate CPU↔GPU bottlenecks. The most actionable signals are high GPU utilization (targeting ~90%+) and trace patterns showing whether the GPU is continuously executing kernels or idling due to synchronization or host-side work. The payoff is faster iteration: failures become loud and discoverable, and slow training becomes diagnosable down to specific training-loop steps.
Why bundle linting and formatting into pre-commit instead of running tools manually?
What makes shell scripts a common source of bugs in ML pipelines, and how does the lab mitigate that?
How does the lab evolve from quick assert statements to maintainable testing?
What is a memorization (overfit) test, and why does it matter for training systems?
How does the lab use GPU profiling to decide whether the bottleneck is code or hardware?
Why does the lab recommend optimizing the forward pass first?
Review Questions
- What specific pre-commit hooks and Python tools does the lab mention, and how do they contribute to code reliability?
- How would you interpret a trace where the GPU stream contains frequent gray idle gaps—what does that imply about CPU↔GPU scheduling?
- What training failure modes can memorization tests catch that accuracy-focused tests might miss?
Key Points
- 1
Use pre-commit to run formatting and linting hooks automatically on every git commit, with isolated tool environments to avoid dependency conflicts.
- 2
Configure linting tools with an “escape valve” (targeted ignores) so teams can ship while planning fixes rather than fighting the tooling.
- 3
Treat shell scripts as high-risk: integrate shellcheck and adopt stricter Bash settings so errors terminate the script instead of failing silently.
- 4
Structure tests so they’re discoverable and maintainable: use pytest naming conventions, keep tests in a tests/ folder, and add coverage reporting with codecov.
- 5
Validate training pipelines with memorization tests (overfit a single batch) using PyTorch Lightning’s overfit-batches-style configuration to ensure the model can learn at all.
- 6
For performance, prioritize GPU utilization and trace inspection: colored kernel blocks with minimal idle time indicate the GPU is not waiting on the host.
- 7
Optimize the forward pass first and increase batch size within GPU memory limits to reduce Python overhead relative to GPU compute.