Lab 3: RNNs (Full Stack Deep Learning - Spring 2021)
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
With window width/stride set to 28, sliding-window CNN predictions align with non-overlapping synthetic characters, enabling cross-entropy training to reach ~89–90% validation accuracy.
Briefing
Sequence models for handwritten text recognition take a practical turn in Lab 3: a sliding-window CNN baseline quickly works when characters don’t overlap, but it breaks down once realistic overlap and variable spacing enter the synthetic data. The fix is to switch from plain cross-entropy training to CTC loss, which can learn alignments between the CNN’s per-window character predictions and the final variable-length label sequence. Adding a bidirectional LSTM on top of the CNN further improves accuracy by injecting context across the predicted character sequence.
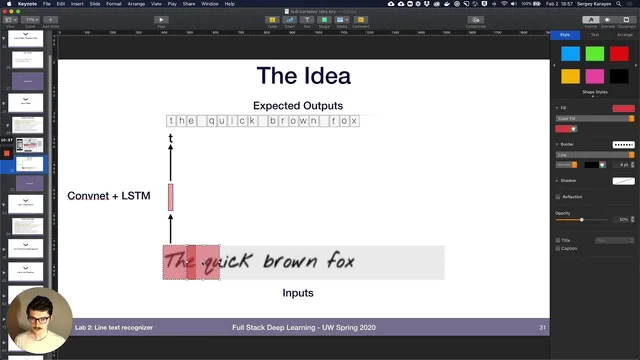
The lab starts from earlier work where MNIST-derived characters and line images are generated, then focuses on recognizing entire lines. It introduces special tokens in the label mapping—most notably a padding token used to extend targets to a fixed maximum length. The first model, “line cnn simple,” applies the same character-level CNN from the previous lab across a line image by sliding a window horizontally. The model computes how many windows fit using window width and window stride, runs each window through the CNN, and produces logits shaped as batch × classes × sequence length. With window width and stride set to 28 (effectively sampling one character at a time), training uses the default cross-entropy loss and reaches validation accuracy around the high 80s to ~90%.
Trouble appears when stride is reduced to create overlapping windows. The ground-truth label length stays fixed to the dataset’s maximum character count, but the model’s output sequence length grows because more windows are produced. After adjusting output length to match the dataset, accuracy still collapses (roughly to the low 50s) because the CNN predictions no longer align cleanly with the underlying non-overlapping character generation process. Making the synthetic data overlap more like the model’s sampling—by increasing overlap to about a quarter—recovers performance into the 70s and can reach the 80s, but a fully realistic setting with variable overlap across characters and writers remains too hard for the simple cross-entropy approach. In that more chaotic regime, accuracy tops out around ~60.
The lab then introduces “line cnn,” a more efficient fully convolutional variant that avoids recomputing convolutions on heavily overlapping windows. It replaces explicit window-by-window CNN calls with a convolutional downsampling stack that yields a sequence of character logits in one pass.
The key upgrade is CTC loss via a dedicated “ctc lit model.” Instead of forcing a one-to-one mapping between windows and target characters, CTC learns the alignment and handles repeated characters and blanks through its collapsing behavior. Training with CTC drives down character error rate substantially (from very high values to around ~70 error rate in validation), while accuracy improves to roughly ~62% in the reported experiment. Finally, a bidirectional LSTM is stacked on top of the CNN logits (summed across directions before a final fully connected layer), pushing character error rate further down to about ~18 and improving overall performance to ~16 character error rate. The lab closes by assigning experimentation: tune window width/stride, LSTM dimensions/layers, and inspect how the greedy decode and character error rate metrics work under CTC.
Cornell Notes
Lab 3 builds a line text recognizer by applying a character CNN across a line image using sliding windows, then progressively fixes the mismatch between window-level predictions and the final character sequence. With non-overlapping sampling (window width/stride = 28), cross-entropy training works well, reaching ~89–90% validation accuracy. Reducing stride to create overlapping windows breaks alignment and drops accuracy to ~52, and variable overlap makes it harder still (best around ~60). Switching the loss to CTC resolves the alignment problem by learning when to emit characters, handling blanks and repeated predictions via CTC’s collapsing behavior. Adding a bidirectional LSTM on top of the CNN sequence further reduces character error rate to about ~16–18.
Why does “line cnn simple” perform well when window stride equals window width, and what changes when stride is smaller?
How does the lab’s “line cnn” improve efficiency compared with “line cnn simple”?
What problem does CTC loss solve in this setup, and how is it implemented here?
Why does variable overlap in the synthetic handwriting data make cross-entropy training fail even when overlap is introduced?
How does adding a bidirectional LSTM change the model’s behavior on top of CTC-trained CNN logits?
What does character error rate (CER) and greedy decode relate to in CTC systems?
Review Questions
- In what way does reducing window stride increase the model’s output sequence length, and why does that disrupt cross-entropy alignment?
- Describe the role of CTC in handling blanks and repeated characters. How does greedy decode relate to CER computation?
- Why might a bidirectional LSTM improve results even when the CNN already produces per-window logits?
Key Points
- 1
With window width/stride set to 28, sliding-window CNN predictions align with non-overlapping synthetic characters, enabling cross-entropy training to reach ~89–90% validation accuracy.
- 2
Overlapping windows (smaller stride) increase the number of output timesteps and break the one-to-one alignment assumption behind cross-entropy, dropping accuracy to around ~52 in the lab’s example.
- 3
Increasing overlap in the synthetic data can partially recover performance, but variable overlap across characters and writers remains too misaligned for cross-entropy to converge well (best around ~60).
- 4
“line cnn” replaces repeated window-by-window CNN calls with a fully convolutional architecture to avoid recomputing convolutions on overlapping regions.
- 5
CTC loss fixes the alignment problem by learning when to emit characters and handling blanks/repeats via collapsing; validation uses greedy decode to produce collapsed predictions for CER.
- 6
Stacking a bidirectional LSTM on top of CNN logits adds sequence context and reduces character error rate further (to roughly ~16–18 in the reported run).