Lab 8: Testing and Continuous Integration (Full Stack Deep Learning - Spring 2021)
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Linting is implemented as a multi-tool static-analysis pipeline (Safety, PyLint, PyCodeStyle, PyDocStyle, MyPy, Bandit, ShellCheck) plus Black formatting to enforce consistent code quality.
Briefing
Lab 8 focuses on making a full-stack handwriting OCR project safer to change by adding automated linting, targeted tests, and continuous integration. The core idea is straightforward: every code push should trigger a repeatable quality check so style issues, common bugs, and broken functionality get caught immediately—before they reach production.
Linting is the first gate. A top-level lint task runs a chain of static-analysis tools: Safety checks Python dependencies for known security vulnerabilities, PyLint performs static code analysis for bugs and style-related problems, PyCodeStyle enforces style conventions, PyDocStyle verifies docstrings, MyPy validates type hints by flagging mismatches (for example, passing an int where a float is expected), Bandit looks for common Python security pitfalls like unsafe use of eval, and ShellCheck covers bash script issues. Configuration lives in files such as .pylintrc and setup.cfg, where teams can set rules like maximum line length and which messages to disable. To keep formatting consistent across developers, the workflow also recommends Black, an automated formatter that normalizes quoting, indentation, and line wrapping in a way that stays compatible with the linting rules.
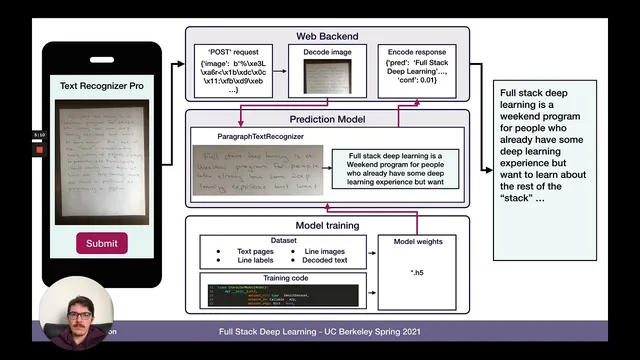
Next come functionality tests for the handwriting-to-text pipeline. A module-level test targets the paragraph text recognizer added in Lab 7. The test disables CUDA to avoid GPU-related variability and uses support assets: images from a dataset plus a JSON file containing ground-truth text and expected character error rate. The test runs the recognizer on each sample, checks that predicted text matches expectations via the character error rate threshold, and records runtime—explicitly aiming to finish within about a minute so it can run frequently.
A separate evaluation test measures model quality more strictly. It loads trained weights and configuration for the paragraph text recognizer and runs on the evaluation dataset while using the GPU, since evaluation is expected to be heavier and CircleCI lacks GPU access. The test asserts both accuracy and speed: the character error rate must stay below a target (around 17% in the current setup), and the runtime must also remain under a defined limit.
Finally, an infrastructure test verifies that the training system still runs end-to-end. It executes the training command against a synthetic “fake image data” module, trains a small model (a ConfNet) for a limited number of epochs, and checks that training completes successfully. This isn’t meant to prove accuracy; it’s designed to catch regressions that would prevent training from running at all.
Continuous integration ties it together. Using CircleCI, the repository is configured with a top-level config.yml that runs linting and tests on every push. The pipeline uses a Python 3.6 Docker image, installs git lfs, ShellCheck, and the exact pinned requirements, then executes lint and tests in sequence. Even if lint fails, tests still run to provide additional signal. The evaluation test is intentionally skipped in CI due to missing GPU resources and runtime constraints. The assignment is to fork the repo, set up CircleCI, and confirm the build turns green.
Cornell Notes
Lab 8 adds a quality-control pipeline for a handwriting OCR system by combining linting, module tests, evaluation tests, and a training “smoke test,” then wiring them into continuous integration. Linting runs multiple static-analysis tools (Safety, PyLint, PyCodeStyle, PyDocStyle, MyPy, Bandit, ShellCheck) plus Black formatting to enforce consistent code style and catch common bugs early. Functionality tests validate the paragraph text recognizer using support images and a JSON file of ground truth and expected character error rate, with CUDA disabled to keep results stable and fast. An evaluation test uses GPU to load trained weights and assert both character error rate and runtime thresholds. A training system test runs training on synthetic “fake image data” to ensure the training command completes successfully. CircleCI runs linting and tests on every push, but skips the GPU-heavy evaluation test.
Why does the linting step run several different tools instead of just one?
How does the paragraph text recognizer functionality test decide whether predictions are correct?
What makes the evaluation test different from the functionality test?
What does the training system infrastructure test verify, and what does it not verify?
Why is the evaluation test skipped in CircleCI?
What does the CircleCI pipeline run on each push?
Review Questions
- Which linting tools would catch type mismatches, and which would catch dependency vulnerabilities?
- How do the functionality and evaluation tests differ in hardware requirements and assertion criteria?
- What is the purpose of using synthetic “fake image data” in the training infrastructure test?
Key Points
- 1
Linting is implemented as a multi-tool static-analysis pipeline (Safety, PyLint, PyCodeStyle, PyDocStyle, MyPy, Bandit, ShellCheck) plus Black formatting to enforce consistent code quality.
- 2
The paragraph text recognizer functionality test uses support images and a JSON ground-truth file to validate predictions via character error rate, with CUDA disabled for stability and speed.
- 3
The evaluation test loads trained weights and runs on the evaluation dataset using GPU, asserting both character error rate (target around 17%) and runtime limits.
- 4
The training infrastructure test is a smoke test: it trains on synthetic “fake image data” to confirm the training command completes successfully, not to prove high accuracy.
- 5
CircleCI is configured to run linting and tests on every push using a Python 3.6 Docker image and pinned requirements.
- 6
GPU-heavy evaluation is intentionally excluded from CI because CircleCI lacks GPU access and the evaluation would be too slow or fail without it.
- 7
The workflow goal is fast feedback: tests are designed to finish quickly enough to run frequently, while CI provides immediate pass/fail signals on commits and pull requests.