Labeling (3) - Data Management - Full Stack Deep Learning
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
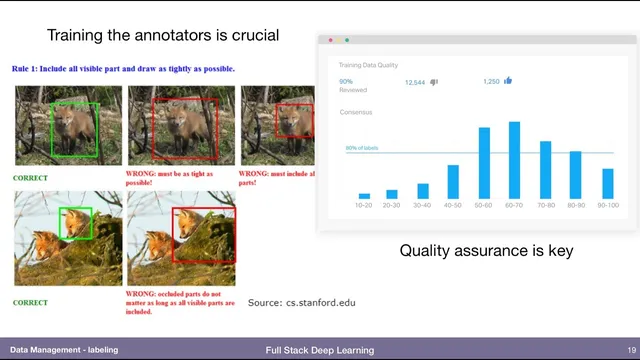
Labeling tool features are standard across providers, but quality hinges on annotator instructions for subjective edge cases (e.g., occlusion boundaries).
Briefing
Data labeling hinges less on the annotation software’s feature list and more on the human decisions inside the labeling workflow—especially when “reasonable” people would draw different boundaries. Vision labeling tools typically offer the same core primitives—bounding boxes, segmentation polygons, keypoints, and cuboids for 3D or video—but quality depends on clear instructions, consistent interpretation, and active quality control. A concrete example is an object partially hidden behind another item: annotators must be told whether to label the entire imagined object or only the visible portion. Without that guidance, label noise rises from subjective judgment calls, and even well-intentioned annotators can drift.
That quality challenge shapes the three main ways teams source labeling labor: hire in-house annotators, crowdsource through marketplaces, or outsource to full-service labeling companies. Hiring directly offers tight control and faster iteration once trusted annotators are identified, including the ability to promote top performers into quality control roles and secure the work via contracts. The tradeoffs are cost, slower scaling (finding and managing real people takes time), and administrative overhead. Crowdsourcing—via services such as Amazon Mechanical Turk—can reduce cost and speed up throughput, but it adds complexity because annotators are transient and often poorly paid, which typically requires an additional quality-control layer.
Full-service data labeling companies aim to remove that operational burden by providing both the annotation interface and the quality assurance machinery. The workflow often looks like: spend a few days evaluating vendors, create a gold-standard labeled dataset internally to understand the true labeling complexity, send that same dataset to candidate providers, and compare their outputs against the internal standard. Pricing matters because vendors charge for recruiting labor, enforcing quality, and managing the process. Examples mentioned include Figure Eight (formerly CrowdFlower), which has labeled over 100 million images and accumulated over 1 billion human judgments by 2018, and Scale AI, which is positioned as an API-like service for labeling new image content. Other providers include Labelbox and Supervisely, while Prodigy is highlighted as an annotation tool that supports active learning and can reduce the amount of labeling needed by prioritizing uncertain samples.
When teams can’t afford heavy quality control, the transcript’s practical stance is blunt: robustness to bad samples can’t be assumed without seeing the relevant distribution. Models may generalize to unseen conditions, but there’s no reliable way to guarantee resilience to specific outliers unless those cases are labeled, tested, and then incorporated into training if needed.
Finally, the discussion turns to aggregation and “subjective” labels. If multiple annotators label the same task, teams can use majority vote or averaging for objective outputs like bounding boxes. For ranking or search relevance—where people disagree—there are multiple strategies: bin items into clearly high/low categories and treat the ambiguous region as noisy, or frame ranking as a regression problem by predicting average rank. Related questions about leveraging negative examples (e.g., images a user didn’t choose, or search links a user didn’t click) remain an active research area because “not chosen” doesn’t always mean “incorrect”—it may reflect randomness or user behavior rather than ground truth.
Cornell Notes
Labeling quality depends on human judgment, not just tool features. Even with standard primitives like bounding boxes and segmentation, teams must provide unambiguous instructions for edge cases (e.g., partially occluded objects) and enforce quality through training and review. Labor can be sourced by hiring in-house (high control but costly), crowdsource marketplaces like Amazon Mechanical Turk (cheaper but needs extra quality control), or outsource to full-service vendors such as Figure Eight or Scale AI (faster operationally but pricier). If quality control is limited, robustness to outliers can’t be guaranteed without labeling and testing those cases, then adding them to training. For subjective tasks like ranking, aggregation may use binning rules or regression-style targets like average rank.
Why do labeling instructions matter as much as the labeling tool’s features?
What are the tradeoffs between hiring annotators, crowdsource labor, and using full-service labeling companies?
How should a team evaluate labeling vendors before scaling up?
What does the transcript say about making models robust when label quality control is limited?
How can multiple annotators’ outputs be combined when labels are subjective (like ranking)?
Can “negative” user feedback (not choosing an item) be treated as ground truth?
Review Questions
- What edge-case decision in labeling requires explicit instructions to reduce subjective disagreement, and why?
- Compare how quality control needs differ between in-house annotators, Amazon Mechanical Turk-style crowdsourcing, and full-service labeling vendors.
- For ranking tasks with annotator disagreement, what two aggregation strategies are suggested, and how do they differ conceptually?
Key Points
- 1
Labeling tool features are standard across providers, but quality hinges on annotator instructions for subjective edge cases (e.g., occlusion boundaries).
- 2
Quality assurance is essential because reasonable people can disagree; tie-breaking rules and monitoring reduce label noise.
- 3
In-house annotators provide maximum control and allow building a trusted quality-control pipeline, but they cost more and scale more slowly.
- 4
Crowdsourcing can be cheaper and faster, yet transient annotators typically require an additional quality-control layer.
- 5
Full-service labeling companies shift operational burden to vendors; teams should validate them using a gold-standard dataset and output comparisons.
- 6
Model robustness to outliers can’t be assumed without labeling and testing those cases; failures should feed back into training data.
- 7
For subjective tasks like ranking, aggregation may use binning rules or regression targets such as average rank rather than forcing a single “true” ordering.