Labs 1-3: Introduction to the Text Recognizer Project - Full Stack Deep Learning - March 2019
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
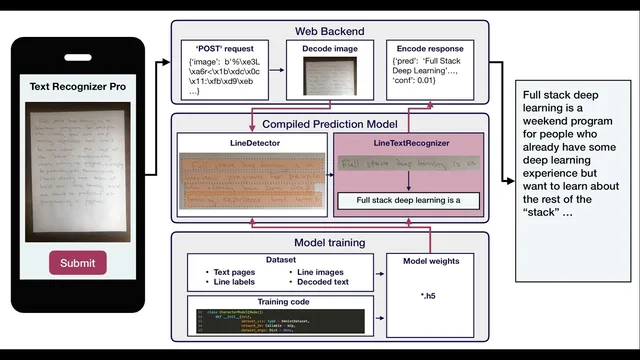
The system is organized as a web backend that decodes an uploaded image, a deployed prediction model that runs inference, and a response that returns transcribed text.
Briefing
Handwritten-text recognition is built as a full pipeline: a web backend accepts an encoded image, a deployed “compiled prediction model” runs inference, and the system returns transcribed text. The core architecture splits recognition into two learned stages—first detecting each text line, then recognizing the characters within that line—so the model can focus on smaller, more learnable visual units before assembling the final output.
At the system level, the web backend receives a POST request containing an encoded image, decodes it into a format the model can process, and sends it to a prediction model packaged for deployment. That prediction model is produced by separate training code that learns weights and wraps them in application-ready logic. In this project’s design, the deployed model is treated like a compiled artifact: weights live alongside inference code so production can serve predictions without dragging in the full training toolchain.
The labs then zoom in on what a “mature” machine learning codebase looks like from training through deployment. The repository is organized into clear layers: an API folder for serving predictions (including a Flask server, tests, Docker configuration, and an AWS Lambda deployment descriptor), a data folder that stores download specifications rather than large datasets, and an evaluation area for quick model checks and unit-test-like scripts. Model and training logic are separated so that deployment can ship only what’s needed for inference. Within training, networks are defined as relatively “dumb” architectures, while models wrap the network with dataset formatting, loss functions, optimization, and training loops. Weights for production models are stored in a dedicated location, while other experiment weights can live elsewhere (e.g., object storage).
To make experimentation repeatable, the labs introduce experiment management with Weights & Biases (W&B) and emphasize dependency control using pipenv so training environments stay consistent even when libraries like TensorFlow change. A web-based Jupyter Lab environment provides shared access to the same requirements and GPUs, enabling everyone to run the same training and tests.
Lab 2 starts with a simpler task: predicting a single handwritten character using the EMNIST dataset (handwritten digits and letters). It demonstrates baseline network options such as an MLP that flattens 28×28 images into vectors and a LeNet-style convolutional network. A key software pattern appears again: networks define layers, while model classes provide a uniform interface (including a fit method) that compiles the network with an optimizer and loss, streams data via generators, and hides framework-specific details from training scripts.
Once character prediction works, the labs scale up to line recognition. The proposed architecture uses a sliding window over the line image, applies a convolutional network to each window patch, feeds the resulting sequence of features into an LSTM, and trains with CTC (Connectionist Temporal Classification) loss. CTC handles the mismatch between the fixed-length sequence produced by the model and the variable-length target text by allowing a special blank (epsilon) label and using dynamic programming to compute the probability of the correct transcription across many alignment paths. The result is a system that can learn from unsegmented handwriting—no per-character bounding boxes required—while still producing coherent text strings.
Cornell Notes
The project builds handwritten-text recognition as a full pipeline: a web backend sends an image to a deployed prediction model, which returns transcribed text. The codebase is structured for maturity—separating inference serving (API, Docker, AWS Lambda), data download specs (not large datasets), evaluation/testing scripts, and training code (networks vs models, weights storage). Training begins with a single-character task on EMNIST using baseline networks like an MLP and a LeNet-style CNN, wrapped by model classes that provide a consistent fit/predict interface. Scaling to full line recognition uses a sliding-window CNN feature extractor, an LSTM sequence model, and CTC loss to align variable-length text without explicit character segmentation. This matters because CTC enables end-to-end learning from images to text where character boundaries are unknown.
Why split recognition into line detection and line text recognition instead of doing everything at once?
What does the codebase separation between “networks” and “models” buy you?
How does the single-character training setup on EMNIST work at a high level?
Why does line recognition use a sliding window plus an LSTM rather than a single left-to-right classifier?
How does CTC loss solve the alignment problem for handwriting without character segmentation?
What inputs does the CTC-based line model need that differ from the simpler character model?
Review Questions
- What specific responsibilities belong in “networks” versus “models,” and how does that affect deployment packaging?
- Describe how sliding windows, a CNN feature extractor, and an LSTM combine to turn a line image into a sequence suitable for CTC.
- Why does CTC require dynamic programming, and what role does the blank (epsilon) label play in training and decoding?
Key Points
- 1
The system is organized as a web backend that decodes an uploaded image, a deployed prediction model that runs inference, and a response that returns transcribed text.
- 2
Line-level recognition is modular: a line detector isolates each line, and a line text recognizer converts that line image into characters.
- 3
A production-ready ML codebase separates concerns: API serving, data download specs, evaluation/testing, inference packaging, and training logic.
- 4
Networks define architectures, while models wrap networks with dataset formatting, loss functions, optimization, and a consistent fit/predict interface.
- 5
Training starts with single-character prediction on EMNIST using baseline CNN/MLP architectures before scaling to line recognition.
- 6
Line recognition uses a sliding-window CNN feature extractor feeding an LSTM, trained end-to-end with CTC loss to handle unknown character boundaries.
- 7
CTC’s blank label and decoding rules (collapse duplicates, remove blanks) enable variable-length text transcription from fixed-length model outputs.