Language Performance Comparisons Are Junk
Based on The PrimeTime's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Treat contrived microbenchmarks as exploratory tools, not as general language-comparison evidence.
Briefing
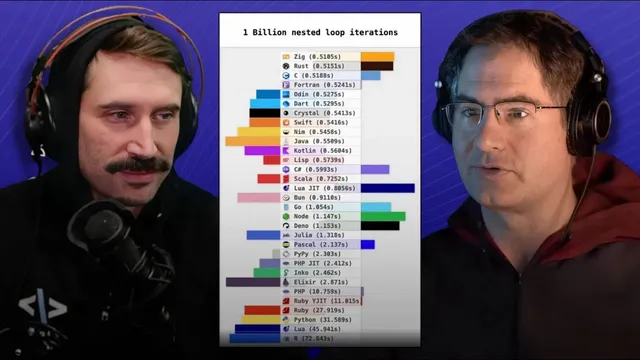
A widely shared “language performance” chart built from a tiny nested-loop microbenchmark is misleading enough to be treated as junk: it ranks languages based largely on how they handle contrived operations (especially integer modulus with an unknown divisor) and on startup/printing overhead, not on real-world loop performance. The core problem is that the benchmark’s structure invites compilers to either (a) do expensive work that dominates runtime or (b) fail to apply optimizations that would normally matter in production code—so the results don’t generalize to how languages behave when writing actual programs.
The discussion starts with a visual and methodological critique: bouncing bars and near-ties (“1 second vs 1.1 seconds”) create a false sense of precision. More importantly, the benchmark doesn’t measure “a billion loop iterations” in any meaningful programming sense. It omits realistic loop bodies, memory behavior, and typical control flow; it also times the entire program run (argument parsing, random-number initialization, computation, and output), meaning startup and I/O costs can swamp the signal when the loop body is engineered to be small.
A key example is how JavaScript runtimes (Node and Bun) can appear similar to compiled languages in such tests because just-in-time compilation and runtime warmup can make the first run look artificially competitive—while the chart still fails to reflect how those languages perform under server-like workloads where differences can be an order of magnitude.
The deeper technical indictment targets the benchmark’s attempt to prevent compiler optimization. The loop body uses a modulus operation where the divisor comes from command-line input and/or runtime-generated values (seeded via time). That “unknown to the compiler” divisor blocks constant-folding and other simplifications. Worse, integer division/modulus is a particularly costly CPU operation: on x86-class cores it has high latency (roughly 20–30 cycles) and low throughput compared with simple arithmetic. As a result, the benchmark becomes a stress test for integer division hardware and for whatever codegen choices happen to survive the benchmark’s anti-optimization tricks.
The conversation also shows how small changes can flip rankings even within the same language. In C, rewriting the modulus using floating-point math (casting to double, computing quotient via truncation, then reconstructing the remainder) can dramatically speed the benchmark because it replaces slow integer division with SIMD-friendly floating-point operations. That transformation can unlock vectorization (e.g., packed double divides) and allow the compiler to process multiple elements per instruction—turning a “loop benchmark” into a “compiler/vectorization benchmark” driven by how the benchmark was written.
Finally, the discussion argues for what a real comparison would require: workloads that resemble actual applications (like multi-game GPU testing in hardware benchmarks), multiple representative tasks, and code that doesn’t intentionally sabotage compiler optimizations. For loop-focused language evaluation, the most relevant modern metric is often vectorization/SIMD behavior; yet the benchmark’s modulus/divide choices largely prevent vectorization, making it a poor proxy for performance in real numerical or data-parallel code. The conclusion is blunt: this particular benchmark should not be used to choose languages or to make general performance claims; it’s better treated as an exploratory demonstration of how compilers and CPUs react to contrived modulus-heavy code.
Cornell Notes
The “language performance” chart is unreliable because it’s built on a contrived microbenchmark that times program startup and output while engineering the loop body to resist compiler optimizations. The benchmark’s dominant cost comes from integer modulus/division with an unknown divisor, which is expensive on CPUs and blocks constant-folding and vectorization. Small rewrites can radically change results—even within the same language—because compilers may switch from slow integer division to SIMD-friendly floating-point math. A meaningful language comparison would need real workloads and representative loop-heavy tasks, not a synthetic loop designed to “thwart” optimization.
Why do tiny microbenchmarks with contrived loops produce misleading language rankings?
How does “unknown to the compiler” modulus sabotage optimization?
Why is integer division/modulus such a big deal for performance?
How can rewriting modulus in C using floating-point math make it faster?
What would a better loop-focused language benchmark look like?
Why are “near ties” and bouncing charts especially dangerous for interpretation?
Review Questions
- What specific benchmark design choices cause the results to reflect integer division behavior and compiler thwarting rather than general loop performance?
- Explain how “unknown divisor” modulus affects compiler optimizations and CPU instruction selection.
- Give an example of how a seemingly small code rewrite could change vectorization and therefore drastically alter benchmark outcomes.
Key Points
- 1
Treat contrived microbenchmarks as exploratory tools, not as general language-comparison evidence.
- 2
Avoid interpreting small timing gaps (like 1.0s vs 1.1s) as meaningful language performance differences.
- 3
Recognize that timing the entire program run (startup, RNG setup, argument parsing, output) can dominate when the loop body is engineered to be small.
- 4
Understand that integer modulus/division with an unknown divisor is a high-latency, low-throughput CPU bottleneck that can overwhelm other factors.
- 5
Expect compilers to behave differently depending on whether modulus can be constant-folded or vectorized; benchmark structure can block or enable these optimizations.
- 6
For loop performance comparisons, prioritize workloads and code shapes that allow vectorization/SIMD, since modern “fast loops” often depend on that.
- 7
A fair language comparison requires representative, real workloads and consistent implementations, not synthetic loops designed to prevent optimization.