Large Scale Reward Modeling | Jonathan Ward | OpenAI Scholars Demo Day 2021
Based on OpenAI's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Reward modeling for informal tasks can be trained from internet preference signals such as Reddit upvotes, avoiding expensive interactive labeling.
Briefing
Large-scale reward modeling can be trained from cheap, naturally occurring preference signals on the internet—without the costly, researcher-guided feedback loops used in earlier work—and it can still generalize to unseen comparisons. Jonathan Ward’s demo centers on learning what makes one response “better” than another in an informal, hard-to-define domain: creative writing. Instead of formal scoring functions, the approach treats human preference as a learnable pattern extracted from public ratings, then uses that learned reward model to steer a story-writing system.
The core setup uses Reddit’s r/writingprompts, where writers submit short story responses to a prompt and the community votes them up or down. Those vote totals become an aggregate proxy for preference. Ward trains three linked models: a generative model that produces story responses from prompts, an evaluative model that takes a prompt plus two candidate responses and predicts which one is preferred, and a gameplay/agent model that starts from the generative model and is further trained using the evaluative model’s pairwise judgments. This sequence mirrors how an agent can learn to act by optimizing against a learned reward signal.
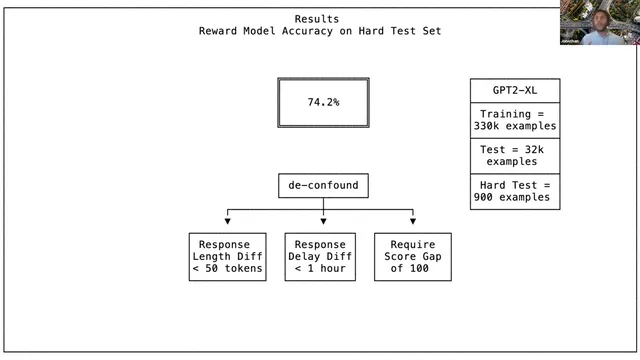
The key empirical question is whether the reward model captures genuine preference rather than superficial shortcuts. Ward reports a hard test designed to reduce confounds such as response length and response timing. The evaluation filters to comparisons where candidate responses are roughly similar in length and created around the same time, aiming to prevent the model from learning that “longer” or “faster” automatically wins. Under this controlled test, the reward model reaches 74.2% accuracy on held-out comparisons.
Ward contextualizes that number by showing how accuracy changes with training set size and model capacity. Larger models learn faster and all model sizes trend toward a similar performance ceiling near 74.2%. Increasing the number of training examples continues to help, especially for smaller models, but gains diminish as performance saturates. The result suggests two constraints: model capacity matters for learning efficiency, while the ultimate limit may be driven by noise in human preference labels and the inherent variability of what people like.
The demo also points to a next step: transfer across tasks and communities. If reward models trained on many subreddits can be tested on new, unseen writing tasks, they would better match real-world settings where feedback is sparse and expensive. Ward frames internet feedback as a form of “pre-training” (broad, abundant signals) and interactive human feedback as “fine-tuning” (carefully curated, expertise-driven corrections).
A cautionary note follows: Reddit is not representative of the globe, so bias is unavoidable if training relies on a single platform. The proposed remedy is balancing internet signals with additional, more curated datasets—potentially including expert-written examples and broader demographic coverage—to make learned notions of “good” less parochial.
Cornell Notes
Reward modeling for informal human preferences can be learned from inexpensive internet signals. Using Reddit’s r/writingprompts, Ward trains an evaluative model that predicts which of two story responses is preferred, then uses it to further train a story-generating agent. The reward model is tested on a “hard” set designed to remove shortcuts tied to response length and timing, and it achieves 74.2% accuracy on unseen comparisons. Accuracy improves with more data and larger models, but performance converges toward a ceiling near 74.2%, suggesting label noise and preference variability. The next direction is transfer across subreddits and tasks, while addressing platform bias by combining internet feedback with more balanced, curated datasets.
How does the project turn Reddit activity into a reward signal for training?
What are the three models in the system, and what role does each play?
Why was the test set designed to be “hard,” and what confounds were targeted?
What does the 74.2% accuracy result mean in context?
How does model size and training data affect performance, according to the learning curves?
What bias concern was raised, and what mitigation strategy was proposed?
Review Questions
- What training objective does the evaluative model use, and how is it constructed from Reddit voting data?
- Which specific confounds were filtered out to prevent the reward model from exploiting shortcuts like length or timing?
- Why might reward-model accuracy converge to a ceiling even as model size increases?
Key Points
- 1
Reward modeling for informal tasks can be trained from internet preference signals such as Reddit upvotes, avoiding expensive interactive labeling.
- 2
A three-stage pipeline links a generative story model, a pairwise evaluative reward model, and an agent model trained to optimize against that reward.
- 3
Generalization is assessed on held-out comparisons using a hard test set that filters out confounds tied to response length and response timing.
- 4
Learning curves show larger models learn faster, but performance saturates near 74.2% accuracy, suggesting a limit from noisy preference labels.
- 5
Internet feedback is positioned as broad “pre-training,” while contractor-based interactive feedback functions like targeted “fine-tuning.”
- 6
Platform bias is unavoidable when relying on a single community; mitigation requires balancing internet data with curated, more representative datasets.
- 7
A next research step is transfer across subreddits and tasks to build reward models that work when feedback is sparse and expensive.