Lecture 13: ML Teams (Full Stack Deep Learning - Spring 2021)
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Machine learning teams are uniquely hard to manage because progress is non-linear, timelines are uncertain, and leadership expectations often don’t match ML realities.
Briefing
Machine learning teams fail or succeed less on model quality alone and more on how organizations staff roles, structure accountability, and manage uncertainty. The lecture frames ML management as a technical leadership problem: hiring is harder, timelines are fuzzier than in software, and leadership often lacks a shared understanding of what “progress” means when experiments can stall for weeks.
It starts with why ML teams are uniquely difficult to run. ML talent is expensive and scarce, and the work depends on multiple specialized roles—product, data, engineering, deployment, and research—often with unclear timelines and high uncertainty. Technical debt is also harder to contain because the field moves quickly, and leadership expectations can be misaligned since many executives understand software delivery but not the iterative, probabilistic nature of ML development.
The lecture then maps common roles inside ML organizations: ML product managers prioritize and translate business goals into plans and design artifacts; DevOps engineers deploy and monitor production systems; data engineers build and maintain data pipelines and storage; ML engineers train and productionize prediction models, often using tools like TensorFlow alongside Docker for deployment; ML researchers train models for forward-looking or less production-critical work and deliver reports on performance and usefulness rather than deploying themselves; and “data scientist” is treated as a catch-all that can mean anything from ML-adjacent engineering to business analytics and SQL-driven dashboards. A key hiring implication follows from this: “data scientist” and “ML engineer” are not interchangeable titles.
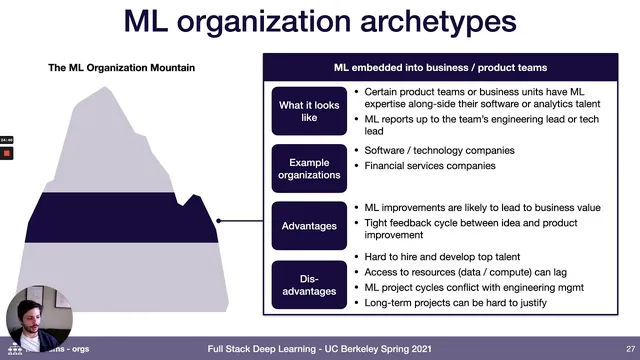
Next comes a “machine learning organization mountain,” describing how companies typically mature. At the base are nascent, ad hoc efforts—often common outside tech-heavy industries—where joining can offer low-hanging wins but also little internal support and difficulty retaining talent. The next stage centralizes ML into an R&D group that runs experiments and produces proof-of-concept reports; it can attract researchers and pursue longer-term priorities, but it struggles with data access and often fails to translate prototypes into business value. A common middle stage embeds ML practitioners into product teams without a centralized ML function, creating tight feedback loops and faster path to production impact, but it can isolate ML talent from peers and make long, uncertain ML cycles hard to fit into engineering planning. Another stage centralizes ML as an independent function reporting to senior leadership, improving data access and talent density, but slowing feedback because models must be handed off to product teams. The top target is a “machine learning first” setup: central ML expertise for infrastructure and high-risk work, plus ML capability embedded across product lines for quick wins and deployment.
Finally, the lecture turns to management and hiring. ML progress is non-linear and hard to forecast; early gains can flatten, and projects can stall without measurable improvement. To manage this, it recommends probabilistic planning—assigning success probabilities to tasks and maintaining a portfolio of parallel approaches rather than a single critical path. It also emphasizes measuring inputs (execution quality on attempted work) rather than only outcomes, keeping researchers and engineers tightly coupled, and building fast end-to-end prototypes to communicate progress. Leadership education is treated as essential, especially to avoid hype-driven status updates that ignore uncertainty. On hiring, the lecture highlights a talent gap and suggests practical sourcing methods (papers, re-implementations, conferences) and more flexible hiring strategies (junior hires, targeted skill requirements, and publication-quality signals for researchers). It closes with interview patterns—pair debugging, math puzzles, take-homes, applied ML assessments—and a job-search strategy that leans on projects and demonstrable ML execution to break into the field.
Cornell Notes
Machine learning teams are harder to manage than traditional software teams because ML work is uncertain, progress is non-linear, and leadership often lacks a shared understanding of ML timelines. The lecture lays out how ML organizations evolve—from ad hoc experimentation to centralized R&D, to embedded ML in product teams, to independent ML functions, and ultimately to “machine learning first,” where central expertise supports ML across every product line. It also breaks down common ML roles (ML product manager, DevOps, data engineer, ML engineer, ML researcher, and the catch-all “data scientist”) and shows how their skills and outputs differ. For management, it recommends probabilistic planning, parallel experimentation, input-based performance measurement, and fast end-to-end prototypes to communicate progress. Hiring guidance focuses on the AI talent gap and on sourcing candidates through publications, re-implementations, and conferences, while tailoring skill requirements to the role.
Why does ML team management feel fundamentally different from managing software teams?
How do the lecture’s ML roles differ in day-to-day responsibility and deliverables?
What does the “machine learning organization mountain” say about how companies structure ML over time?
What management practices help when ML timelines are uncertain?
How should hiring teams think about sourcing and evaluating ML candidates?
What kinds of assessments show up in ML interviews, according to the lecture?
Review Questions
- Which organizational archetype on the “machine learning organization mountain” best matches a company that wants fast product feedback, and what trade-off does that structure create for ML talent development?
- How does probabilistic planning change day-to-day decision-making on an ML project compared with waterfall planning?
- What signals does the lecture recommend for evaluating ML researchers (publication quality vs quantity), and how should those signals differ from hiring ML engineers?
Key Points
- 1
Machine learning teams are uniquely hard to manage because progress is non-linear, timelines are uncertain, and leadership expectations often don’t match ML realities.
- 2
ML organizations need multiple specialized roles—ML product management, DevOps, data engineering, ML engineering, ML research, and a careful interpretation of “data scientist” titles.
- 3
Companies typically mature from ad hoc ML efforts to centralized R&D, then to embedded ML in product teams or independent centralized ML functions, eventually aiming for a “machine learning first” structure.
- 4
Probabilistic planning—assigning success probabilities and maintaining a portfolio of approaches—reduces the risk of betting on a single critical path in ML.
- 5
Performance management should emphasize inputs and execution quality rather than only whether a specific experiment succeeded.
- 6
Researchers and engineers should collaborate closely, and teams should build fast end-to-end prototypes to communicate progress with concrete metrics.
- 7
Hiring for ML should reflect the talent gap: use publications, re-implementations, and conferences for sourcing, and tailor skill requirements to the specific ML role.