Lecture 5: ML Projects (Full Stack Deep Learning - Spring 2021)
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
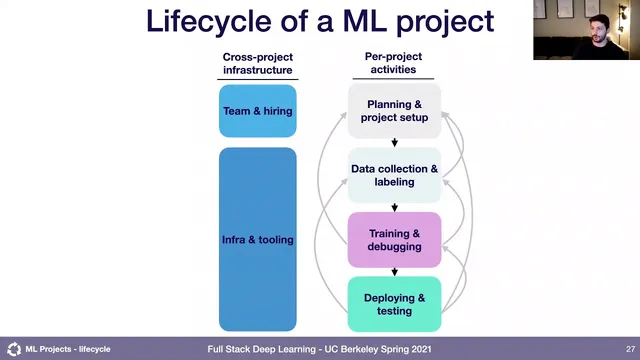
Treat ML development as an iterative lifecycle with feedback loops across planning, data, training/debugging, and deployment/testing.
Briefing
Machine learning projects fail less because models are “bad” and more because teams start with unclear goals, unrealistic feasibility assumptions, and weak planning for how a model will behave in the real world. A widely cited industry statistic—often framed as “85 percent of AI projects fail”—isn’t about a precise number so much as a warning: turning a trained model into a production system is hard, and many efforts get stuck in proof-of-concept demos, unclear success criteria, or poor scoping and management.
The lecture’s core prescription is to treat ML work like engineering with a full lifecycle, not a one-way pipeline from training to deployment. Planning and project setup come first: define requirements, goals, and constraints (including ethical considerations when relevant), then move into data collection and labeling. Crucially, the process is iterative. Teams should expect to loop back when data is too hard to obtain, labels are unreliable, or requirements conflict—such as accuracy versus latency trade-offs. Training and debugging is where teams build baselines (sometimes non-ML, like rule-based or OpenCV approaches), reproduce state-of-the-art results, and then iterate on model improvements; failures here can trigger more data collection or even a rethink of the task itself. Deployment and testing then includes pilots, regression tests to prevent regressions, and checks for bias. Even after rollout, performance gaps in the pilot or production often require looping back to training, data, or even the original success metric and requirements.
From there, the lecture shifts to how to choose which ML projects to pursue. Prioritization uses two axes: potential impact and feasibility. High-impact opportunities often come from “cheap prediction” (automating expensive expert judgments), reducing friction in the product experience, automating complicated manual processes, or replacing brittle rule-based logic with learned behavior. Feasibility is driven by three cost drivers: data availability (acquisition difficulty, labeling cost, stability, and security constraints), accuracy requirements (how costly wrong predictions are and how frequently the system must be correct), and intrinsic problem difficulty (whether the problem is well-defined as ML, whether similar work exists, compute/inference constraints, and whether a human can solve it from the same inputs).
The lecture also emphasizes that accuracy demands can explode costs. Raising required accuracy by “more nines” typically requires substantially more data and higher-quality labels, so project cost can scale super-linearly with stringent accuracy targets.
To make project development manageable, teams should pick a single optimization metric at a time—even though real systems need multiple metrics like latency and robustness. The metric should reflect production requirements, and it should be revisited as the team closes gaps. For example in a running case study on pose estimation for robotic grasping, the system’s requirements include position error under about one centimeter, angular error within roughly five degrees, and inference under 100 milliseconds; early work should prioritize the biggest shortfall (e.g., angular error) and only later optimize runtime.
Finally, baselines are treated as essential guardrails. Good baselines provide a lower bound on achievable performance and help diagnose whether the model is underfitting or overfitting—using the same loss curves but different baseline comparisons to decide what to fix next. Baselines can be external (published results), internal (scripted heuristics, linear models), or human performance, with trade-offs between baseline quality and labeling cost. The lecture closes by tying everything together: iterate through the lifecycle, choose feasible high-impact projects, optimize with disciplined metrics, and use baselines to ensure effort targets the real bottleneck.
Cornell Notes
The lecture argues that ML success depends less on model training and more on disciplined project engineering: planning, data, training/debugging, and deployment/testing—repeated in loops as new evidence appears. Many projects fail because they’re poorly scoped, technically infeasible, or lack clear success criteria, so teams must assess feasibility using data availability, accuracy requirements, and intrinsic problem difficulty. During development, teams should optimize one metric at a time (even if production needs multiple metrics) and revisit that metric as performance improves. Baselines are the diagnostic foundation: comparing training/validation behavior against strong baselines reveals whether the next step should address underfitting or overfitting. Together, lifecycle iteration, metric focus, and baseline-driven debugging reduce the risk of getting stuck in demos that never become reliable production systems.
Why does the lecture treat ML projects as iterative loops rather than a linear pipeline?
What makes a machine learning project “feasible,” and how do data, accuracy, and problem difficulty drive cost?
Why does the lecture warn that tightening accuracy targets can make projects dramatically more expensive?
How should teams choose a single metric when real systems care about multiple metrics?
What do baselines do beyond “measuring performance,” and how do they guide next steps?
How do the lecture’s project archetypes change what “success” and “risk” look like?
Review Questions
- What specific conditions would justify looping back from deployment/testing to data collection, and what evidence would trigger that loop?
- How would you decide which metric to optimize first if multiple production requirements are not yet met?
- Give an example of how two different baselines could change the interpretation of the same training/validation loss curves.
Key Points
- 1
Treat ML development as an iterative lifecycle with feedback loops across planning, data, training/debugging, and deployment/testing.
- 2
Use feasibility assessment to avoid doomed projects by evaluating data availability, accuracy requirements, and intrinsic problem difficulty.
- 3
Prioritize projects using an impact-versus-feasibility lens, and look for opportunities like cheap prediction and friction reduction in products.
- 4
Optimize one metric at a time during model iteration, using thresholds for other metrics, and revisit the chosen metric as gaps close.
- 5
Expect accuracy targets to drive cost super-linearly; “more nines” usually means much more data and higher-quality labels.
- 6
Build strong baselines (scripted, external, and human where appropriate) to diagnose underfitting versus overfitting and to set realistic expectations.
- 7
Design product and system guardrails (including human-in-the-loop or constrained scopes) to make high-risk ML applications more feasible.