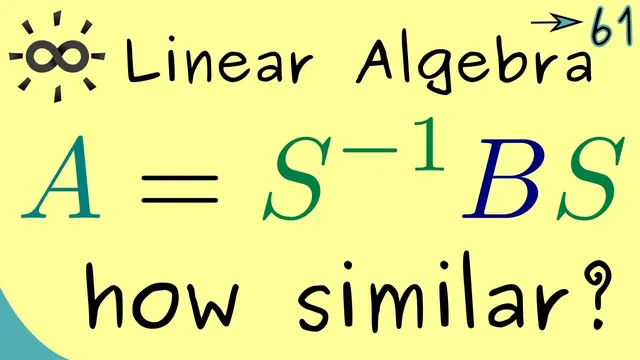
Linear Algebra 61 | Similar Matrices
Based on The Bright Side of Mathematics's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Two matrices A and B are similar when an invertible S exists with A = S^{-1}BS, representing the same linear map in different coordinates.
Briefing
Similar matrices are the algebraic way to say two matrices represent the same linear map in different coordinate systems: if there exists an invertible matrix S such that A = S^{-1}BS (equivalently S^{-1}BS = A), then A and B are similar. This invertible change of basis matters because it preserves core structural features of the associated linear maps. In particular, injectivity is identical for the two matrices: A is injective if and only if B is injective. The same kind of invariance also holds for surjectivity, reflecting that the kernel and image dimensions behave consistently under similarity.
The most important spectral consequence is that similar matrices share the same characteristic polynomial. For a matrix A, the characteristic polynomial is P_A(λ) = det(A − λI), a degree-n polynomial. Using the similarity relation A = S^{-1}BS, the determinant expression can be rewritten by expressing the identity I as S^{-1}S, then factoring out S^{-1} on the left and S on the right. Because determinants are multiplicative, the determinant contributions from S^{-1} and S cancel out (det(S^{-1})det(S) = det(I) = 1), leaving det(B − λI). As a result, P_A(λ) = P_B(λ), so A and B have exactly the same eigenvalues, with the same algebraic multiplicities.
The discussion then connects these invariance results to eigenvector structure. While the eigenvalues and their algebraic multiplicities stay fixed under similarity, the eigen spaces themselves can change after the coordinate transformation. The dimensions of the eigenspaces (geometric multiplicities) are also preserved, but the actual subspaces in the ambient vector space may be different because the change of basis reshapes how vectors are represented.
From there, the transcript moves to a major payoff: for certain classes of matrices, similarity can be used to simplify computation dramatically. Every normal matrix is similar to a diagonal matrix. That includes self-adjoint (Hermitian) matrices, which are normal. In this diagonal form, the diagonal entries are precisely the eigenvalues of the original matrix, repeated according to their algebraic multiplicities—so a normal n×n matrix becomes diagonal with n eigenvalue entries counting multiplicity. Diagonal matrices are far easier to work with than general matrices because many operations (powers, functions of the matrix, solving linear systems) reduce to elementwise operations on the diagonal.
For general square matrices, the strong diagonalization guarantee fails. Instead, one can only ensure a weaker canonical form: similarity to an upper triangular matrix. The eigenvalues still appear on the diagonal with the correct algebraic multiplicities, but there may be nonzero entries above the diagonal. The transcript points to Jordan normal form as the more precise framework for understanding this remaining structure, while noting that the next step before fully using these canonical forms is learning how to compute eigenvectors—since the transformation matrix S and its inverse are tied directly to eigenvectors.
Cornell Notes
Two square matrices A and B are similar if an invertible matrix S exists with A = S^{-1}BS. Similarity corresponds to the same linear map written in different coordinates, so key properties like injectivity (and surjectivity) are preserved. Most importantly, similarity leaves the characteristic polynomial unchanged: det(A − λI) equals det(B − λI), so A and B have the same eigenvalues with the same algebraic multiplicities. Geometric multiplicities (dimensions of eigenspaces) also remain the same, though the eigenspaces themselves can move under the change of basis. This preservation of spectral data motivates diagonalization: every normal matrix is similar to a diagonal matrix, while a general matrix is only guaranteed to be similar to an upper triangular one (with Jordan form describing the finer structure).
What does it mean for two matrices to be similar, and why must S be invertible?
How does similarity guarantee that A and B have the same characteristic polynomial?
What spectral information is preserved under similarity, and what can still change?
Why are normal matrices singled out for diagonalization?
What is the weaker guarantee for an arbitrary square matrix?
Review Questions
- If A = S^{-1}BS, show directly (using determinant properties) why det(A − λI) = det(B − λI).
- Which quantities are preserved under similarity: eigenvalues, algebraic multiplicities, geometric multiplicities, and eigenspaces themselves?
- Why does diagonalization hold for normal matrices but not for arbitrary matrices? What form replaces it?
Key Points
- 1
Two matrices A and B are similar when an invertible S exists with A = S^{-1}BS, representing the same linear map in different coordinates.
- 2
Similarity preserves injectivity and surjectivity of the associated linear maps.
- 3
The characteristic polynomial is invariant under similarity: det(A − λI) = det(B − λI).
- 4
As a consequence, similar matrices have identical eigenvalues with the same algebraic multiplicities.
- 5
Geometric multiplicities (dimensions of eigenspaces) are preserved under similarity, even though the eigenspaces themselves may change.
- 6
Every normal matrix is similar to a diagonal matrix, with eigenvalues on the diagonal repeated by algebraic multiplicity.
- 7
For general matrices, similarity guarantees only an upper triangular form, motivating Jordan normal form for the remaining structure.