Livecoding: ICE and the Factored Cognition Primer by Ought
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
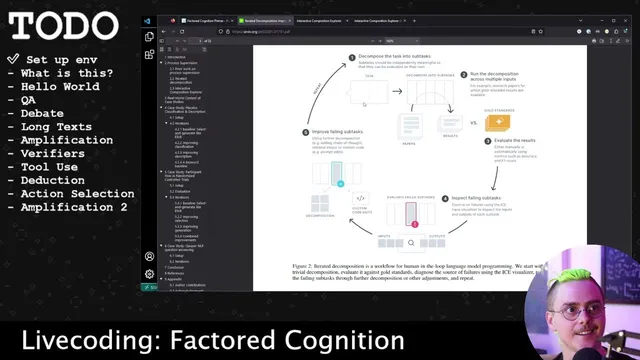
Iterated decomposition improves LLM reliability by evaluating smaller subtasks separately, then using failing-subtask inspection to decide whether fixes belong in prompts, retrieval, code flow, or decomposition.
Briefing
High-reliability language-model apps increasingly come from breaking tasks into smaller, testable steps—then using execution traces to pinpoint exactly which sub-step fails. In this live coding walkthrough of Ought’s “Factored Cognition Primer,” the central idea is iterated decomposition: split a complex goal (like question answering) into meaningful subtasks, evaluate each piece with “gold standards” (human answers, stronger models, or datasets), and then inspect failing subtasks to decide whether the fix belongs in prompting, code flow, retrieval, or even the decomposition itself. That approach boosts reliability compared with end-to-end prompting, and it mirrors how mature software teams build systems: modular components, targeted evaluation, and a feedback loop that improves over time.
The walkthrough then demonstrates the tooling behind that workflow: ICE (Iterative Composition Explorer). Starting from a “hello world” async Python recipe, ICE traces only async functions—so normal synchronous helper code doesn’t clutter the trace. The UI renders a tree/DAG of calls, showing inputs and outputs per async node, and lets developers drill into the exact prompt text and parameters sent to model calls. That trace-first design becomes the debugging backbone once language models and external services enter the picture.
The primer’s first real example is question answering without external context. A prompt is built using F-values (a specialized f-string helper), and the trace shows the full prompt sent to an OpenAI agent completion call. The walkthrough highlights practical prompt hygiene: stripping trailing whitespace matters because tokenizers treat leading spaces differently, and the example uses a stop sequence trick (a closing quote) to prevent completion models from drifting into generating extra, unintended text.
Next comes question answering with context. The system feeds a background snippet (e.g., an event date) and asks a question about a different date to test whether the model correctly reasons about relevance. When the model misbehaves—answering based on the background even when it shouldn’t—the trace confirms the intended context was actually passed, shifting suspicion from “coding mistake” to “model reasoning and prompt design.” The walkthrough then suggests that better relevance handling may require prompt engineering (e.g., instructing the model to verify context relevance) or few-shot examples.
The session also showcases iterative improvement via a “fixer prompt” loop: generate a long, step-by-step answer, then repeatedly ask a second pass to shorten and tighten it until the output converges. ICE makes the cost and iteration count visible, showing how many times the fixer runs before stabilization.
To demonstrate more advanced control, the walkthrough builds a debate workflow where two agents take opposing positions (Alice vs. Bob) for a fixed number of turns, and a judge agent decides the winner. Tracing reveals token/cost growth as the debate context expands, and it even shows how the judge’s final answer can change after seeing the debate.
Finally, the walkthrough moves into long-text and tool use. For long documents, it motivates decomposition into “find relevant sections” plus “answer using those sections” to fit within context windows. For tool use, it implements web search via serp API: the model chooses a query, retrieves results, renders them into a prompt, and then answers using those snippets. Tracing exposes failures like invalid API keys (previously hidden by error-swallowing) and incorrect answers caused by snippet quality. The session then attempts an exercise to fetch and include the first web page’s content, running into practical web constraints (403/forbidden) and HTML parsing challenges—again underscoring why traceable, modular workflows matter.
Overall, the walkthrough frames ICE not as a novelty, but as a development instrument: it turns LLM behavior into inspectable artifacts—prompts, tool calls, intermediate outputs, and iteration counts—so teams can systematically improve reliability rather than guessing where things went wrong.
Cornell Notes
Ought’s “Factored Cognition Primer” argues that higher-reliability LLM applications come from iterated decomposition: split a hard task into smaller subtasks, evaluate each subtask with clear benchmarks, and use trace-based inspection of failures to decide whether fixes belong in prompting, retrieval, or further decomposition. The walkthrough demonstrates ICE (Iterative Composition Explorer), which traces only async functions and renders a call tree with per-node inputs/outputs, making it easier to debug what prompts and tool results actually reached the model. Examples progress from simple QA to context-based QA (where relevance mistakes can be diagnosed via traces), to iterative “fixer” loops that shorten answers until convergence, to debate workflows with a judge agent. Tool use with serp API shows how tracing reveals hidden external-service errors and how snippet quality affects final answers.
Why does iterated decomposition improve reliability compared with end-to-end prompting?
What does ICE trace, and why does that matter for debugging?
How do prompt details like trailing whitespace and stop sequences affect model behavior?
What went wrong in context-based QA, and how did traces help?
How does the “fixer prompt” loop work, and what does convergence look like in practice?
Why does tool use require careful handling of external errors and result formatting?
Review Questions
- How would you design subtask evaluation for a QA system so that failures are attributable to retrieval vs. reasoning?
- What specific trace evidence would convince you that a context-passing bug is not the cause of a model’s wrong answer?
- In a tool-augmented workflow, what are two distinct ways tracing can prevent silent failures from reaching end users?
Key Points
- 1
Iterated decomposition improves LLM reliability by evaluating smaller subtasks separately, then using failing-subtask inspection to decide whether fixes belong in prompts, retrieval, code flow, or decomposition.
- 2
ICE traces only async functions, producing a readable call tree with per-node inputs/outputs—making it easier to verify what prompts and tool results actually reached the model.
- 3
Prompt hygiene matters: stripping trailing whitespace avoids tokenization quirks, and stop sequences can prevent completion models from generating extra unintended content.
- 4
Context-based QA failures can be diagnosed by traces that confirm the exact background text sent to the model, shifting debugging toward relevance reasoning and prompt design.
- 5
Iterative improvement (fixer loops) can shorten and refine outputs over multiple passes; tracing makes iteration count and cost visible so convergence behavior can be measured.
- 6
Debate workflows (Alice vs. Bob plus a judge) can change final answers after seeing opposing arguments, but token/cost grows as debate context accumulates.
- 7
Tool use with web search requires robust error visibility and careful result rendering; tracing helps catch hidden API failures and explains why snippet quality drives answer accuracy.