LLMOps (LLM Bootcamp)
Based on The Full Stack's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Start with GPT-4 for most proof-of-concepts, then adjust based on latency, cost, fine-tuning needs, and licensing/security constraints.
Briefing
LLMOps is less about picking the “best” language model and more about building a reliable production loop: choose a model with the right trade-offs, manage prompts like versioned experiments, evaluate against realistic data, and then monitor outcomes in the wild to catch regressions and new failure modes. The central message is that trust and measurement—not vibes—determine whether an AI feature keeps users or sends them back to older tools.
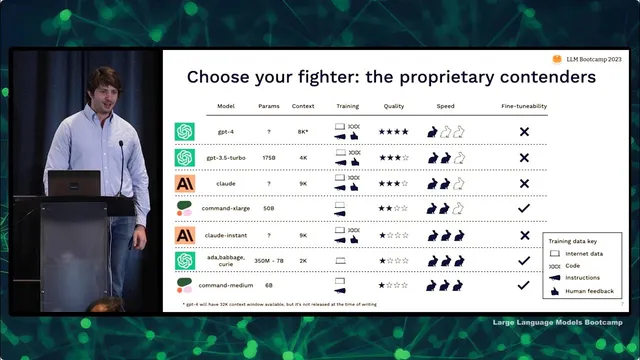
Model choice starts with trade-offs across out-of-the-box quality, inference speed and latency, cost, fine-tuning flexibility, and data security and licensing. There’s no universal winner, but the practical default is to start with GPT-4 unless constraints force a different path. Proprietary models tend to deliver higher quality and are simpler to deploy because they’re accessed via APIs, while open-source models often require more work to serve and may come with licensing friction. For open-source, license type matters: permissive licenses like Apache 2.0 allow broad use, restricted licenses limit commercial use in some way, and “open source” models under non-commercial terms effectively block production use.
Within proprietary options, GPT-4 is positioned as the highest-quality model available, with GPT-3.5 and Claude close behind depending on what output quality you prioritize. Fine-tuning is highlighted as a differentiator: Cohere’s larger models are presented as the best bet when customization is a priority, while OpenAI and Anthropic have moved away from reinforcement learning from human feedback. When teams need lower cost or faster responses, they can downshift to other models, accepting quality trade-offs.
Open-source options are grouped by both model capability and license permissibility. Flan T5 and T5 are recommended as “best bets” for permissive licensing with decent results. Pythia and its instruction-tuned variants (including Dolly) have gained attention, but the fine-tuned licenses may not be usable for meaningful production. Stability AI’s Stable LM and instruction-tuned versions are flagged as too new to judge fully, though they’re worth watching. Llama and its ecosystem fine-tunes (Alpaca, Vicuna, Koala) are described as community favorites for tinkering, but restricted licenses make them poor fits for production. Older OPT is useful mainly for research that mirrors the original GPT-3-era training style, while Bloom and GLM are dismissed as lower quality with unhelpful licenses.
Evaluation and prompt management are treated as the operational heart of LLM systems. Prompt iteration today often feels like 2015-era deep learning—fast experiments without strong tooling for tracking what changed, what worked, and what regressed. The recommended progression is pragmatic: start with ad hoc testing, move to Git-based prompt tracking for most teams, and consider specialized prompt experiment tools only when collaboration, parallel evaluation, or stakeholder workflows demand it. The reason measurement matters is that LLM outputs are qualitative and drift is inevitable; improving a prompt on a handful of cherry-picked examples can degrade performance elsewhere.
Testing language models requires building evaluation sets incrementally: start small, add hard failures and diverse use cases, use the model to generate test cases (e.g., via Auto evaluator), and keep expanding as users reveal new problems. Metrics can be automated when there’s a clear answer (accuracy), a reference answer (reference matching), a prior model output (which-better), or human feedback (feedback-incorporated), and otherwise rely on structured checks or model-judged grading. Even with automation, manual review remains necessary.
After deployment, monitoring should focus on user outcomes first, then proxy signals (like response length preferences), and finally specific production failure modes: hallucinations, overly long answers, refusals, latency, prompt injection, and toxicity. User feedback feeds back into prompt updates and, when feasible, fine-tuning. The lecture ends with a “test-driven/behavior-driven” development loop: log interactions, extract themes, generate new tests, iterate prompts, and optionally fine-tune—creating a virtuous cycle that makes the system more robust as it learns from real usage.
Cornell Notes
LLMOps centers on turning language-model experimentation into a production-grade feedback loop. Model selection depends on trade-offs across quality, latency, cost, fine-tuning needs, and—critically—data security and licensing. Because LLM behavior is qualitative and production data drifts from training assumptions, prompt changes must be tracked and evaluated on realistic, expanding test sets rather than cherry-picked examples. Teams should manage prompts like versioned experiments (often with Git), build evaluation sets incrementally using hard failures and diverse cases, and use automated metrics where possible while keeping manual checks. Once deployed, monitoring should prioritize user outcomes and detect common failure modes (latency, hallucinations, refusals, prompt injection, toxicity), feeding themes back into prompt iteration and potentially fine-tuning.
Why does the “best model” depend on the use case instead of being a single universal choice?
How should teams think about proprietary vs open-source models in production?
What criteria matter when comparing models, and why are context window and training data emphasized?
Why is prompt engineering often hard to manage without experiment tracking?
How should evaluation sets be built for LLM applications given that outputs are qualitative and drift is inevitable?
What monitoring signals should come first after deployment?
Review Questions
- Which trade-offs (quality, latency, cost, fine-tuning, security, licensing) would push a team away from GPT-4 as the default starting point?
- What are two concrete reasons cherry-picked prompt improvements can still cause regressions in production?
- How would you expand an evaluation set after deployment when new user failure modes appear?
Key Points
- 1
Start with GPT-4 for most proof-of-concepts, then adjust based on latency, cost, fine-tuning needs, and licensing/security constraints.
- 2
Treat licensing as a first-class requirement for open-source models; permissive licenses are production-friendly, while non-commercial “open source” terms can block deployment.
- 3
Compare models using context window, training data mix (internet, code, instructions, human feedback), subjective quality, speed, and fine-tunability—not just parameter count.
- 4
Manage prompts and chains as versioned experiments (often with Git) to prevent lost work and to make regressions debuggable.
- 5
Build evaluation sets incrementally using hard failures and diverse user intents; keep expanding as production drift reveals new problems.
- 6
Use automated evaluation metrics when possible (accuracy, reference matching, which-better, feedback-incorporated, structured checks), but keep manual review for reliability.
- 7
Monitor user outcomes first, then proxy signals and specific failure modes like hallucinations, latency, refusals, prompt injection, and toxicity.