Logseq Meetup #2
Based on Logseq's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Logseq’s refactor extracts a smaller logical core and shifts file reading/writing and much of the complex string/block processing into plugins to reduce core complexity.
Briefing
Logseq’s refactor is reshaping the app around a smaller “logical core” and a plugin-driven architecture—moving file I/O and most string/character processing out of the center so new storage backends and features can be added without rewriting the engine. The immediate payoff is a simpler, more testable system: hundreds of lines were removed from the core, file corruption issues were addressed, and undo/redo was rebuilt with a focus on stability.
Under the new design, writing and reading file content shifts into plugins, leaving the logical core to concentrate on core operations and data flow. The team also introduces a clearer separation of responsibilities: the outliner—the critical component inside the logical core—gets its ordering and byte/string calculations streamlined, while civilization logic and block-related processing move into plugins. That modularity is meant to unlock multiple persistent storage options (for example, markdown files, org-mode files, sci-doc files, or sqlite and other backends) simply by swapping in different “civilization” adapters.
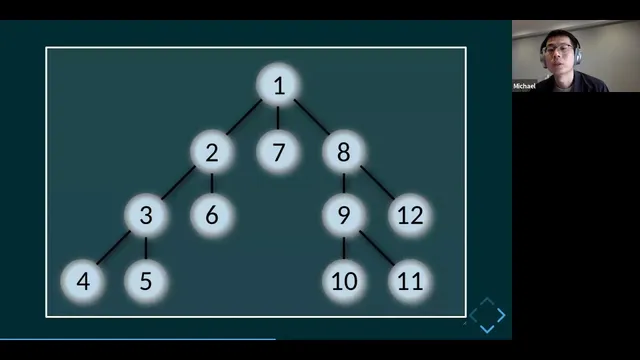
A key structural change is how Logseq models documents. The logical document is treated as a tree, with relationships represented through node identifiers such as id, parent id, and left id. In this model, operations on the tree become simpler, and the system can better manage block relationships. The refactor also changes how pages map to storage: a “page” becomes a special block type rather than a separate file in the same way as before. The whole graph is described as a large tree of logs, where pages act as roots and blocks live beneath them.
To bridge the outliner and plugins, the team adds a middle layer called “hooks.” Hooks sit between the outliner and plugin system, allowing plugins to plug into the lifecycle of outliner operations—supporting use cases like wikis and custom input/output transformations. The goal is to let plugins connect to arbitrary persistent stores, not just markdown-based workflows.
Alongside the architectural refactor, the meetup demonstrates a prototype plugin system in the desktop app. Developers enable it via a developer mode and a plugin entry in the toolbar. The plugin principles emphasized are security/privacy (plugins run in isolated environments such as sandboxed contexts like iframes or web workers) and developer friendliness. A set of sample plugins illustrates what’s already possible: a “hello world” message plugin, a theme/sim plugin with persistent light/dark switching, a community calendar plugin that queries journal data through a plugin API, editor-focused plugins for font customization, a slash-command plugin that currently routes commands through a handler with APIs still under development, and a page/block mapping plugin that displays block levels.
Q&A sharpened timelines and tradeoffs. A refactored desktop testing version is expected in about a week, with remaining plugin APIs and documentation potentially taking around a month. Mobile is on the roadmap but tied to encrypted storage and future real-time collaboration, with no firm date. Undo/redo is acknowledged as tested mainly within Logseq itself, with plans for broader robustness checks. Additional roadmap items include publishing improvements (exporting static pages), faster graph loading for large imports, and UX refinements like sidebar/contents navigation—some of which could be handled via plugins.
Overall, the meetup frames the refactor as a foundation for stability and extensibility: a smaller core, clearer data modeling, and a plugin ecosystem designed to support new storage, UI behaviors, and integrations without destabilizing the engine.
Cornell Notes
Logseq’s refactor is reorganizing the system around a smaller “logical core” and pushing file handling and much of the string/block processing into plugins. The outliner remains the most critical part, but ordering and byte/string calculations are being streamlined, while persistence becomes swappable through different adapters (e.g., markdown or other storage backends). Pages are treated as special block types in a tree-structured graph, and a new “hooks” layer lets plugins intercept outliner lifecycle events to implement features like wikis and custom input/output transformations. A prototype plugin system is already demonstrated in the desktop app, with security/privacy via sandboxing and a developer-friendly workflow, while APIs and documentation are still being completed.
What does “extracting a logical core” change in Logseq’s architecture, and why does it matter?
How does the new data model represent pages and blocks?
What role do “hooks” play between the outliner and plugins?
What does the prototype plugin system enable right now in the desktop app?
What timelines and constraints emerged during Q&A about plugins and mobile?
Review Questions
- How does moving file I/O and string/byte processing into plugins affect stability and extensibility compared with the prior architecture?
- In the refactor’s model, how do pages relate to blocks and how does the tree structure use identifiers like parent id and left id?
- What is the purpose of the hooks layer, and how does it expand what plugins can do beyond simple UI extensions?
Key Points
- 1
Logseq’s refactor extracts a smaller logical core and shifts file reading/writing and much of the complex string/block processing into plugins to reduce core complexity.
- 2
The outliner remains central, with ordering and byte/string calculations moved/simplified to improve robustness and scalability.
- 3
The data model treats the logical document as a tree using node identifiers (id, parent id, left id), making block relationship operations more straightforward.
- 4
Pages become a special block type in the database model, while the graph is handled as a tree of blocks/logs with pages acting as roots.
- 5
A new hooks layer sits between the outliner and plugins, letting plugins intercept outliner lifecycle events and modify input/output block data.
- 6
A prototype desktop plugin system is already usable via developer mode, with security/privacy via sandboxing and sample plugins demonstrating themes, calendars, editor settings, slash commands, and block mapping.
- 7
Q&A suggested about one week for a refactored desktop testing release and around a month for broader plugin API readiness and documentation, while mobile depends on encrypted storage and collaboration features.