Long term credit assignment with temporal reward transp… | Cathy Yeh | OpenAI Scholars Demo Day 2020
Based on OpenAI's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Standard reinforcement learning can struggle with long-delayed rewards because discounting sharply reduces the learning signal for early actions whose payoff arrives much later.
Briefing
Long-delayed rewards can make standard reinforcement learning painfully slow because discounting shrinks the learning signal for actions that only pay off much later. In a key-and-goal gridworld example, an agent can reach the goal, but without a mechanism to properly credit the earlier “pick up the key” action, the value of that early decision becomes nearly invisible—so learning stalls around the baseline reward.
Cathy Yeh’s solution, Temporal Reward Transport (TRT), targets this credit-assignment failure directly. The method starts by identifying which state-action pairs are likely responsible for a distant outcome. It does this using an attention-based “intention mechanism”: after running a full episode rollout, a classifier assigns attention scores across the sequence, producing a heatmap that highlights the frames where the agent’s actions appear most relevant to the eventual outcome. Once those significant state-action pairs are found, TRT “splices” the distal reward back onto them—effectively amplifying the learning signal so the policy gradient can reinforce the earlier actions that mattered.
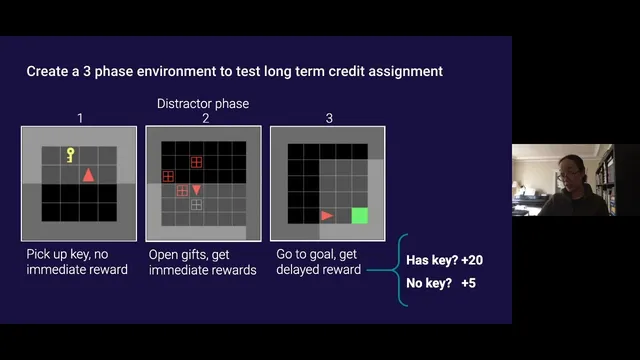
The experiments are designed to stress-test long-horizon learning. The environment has three phases: (1) an empty grid where the agent may pick up a key but receives no immediate reward; (2) a distractor phase filled with gifts that produce immediate rewards; and (3) a final phase where reaching a green goal yields a large bonus only if the key was collected in phase one. If the agent never learns the key behavior, it earns a small score corresponding to reaching the goal without the key.
Across multiple difficulty knobs, TRT consistently improves over a standard Advantage Actor-Critic (A2C) baseline. When the distractor-phase time delay increases—making the key’s payoff even more temporally distant—A2C eventually plateaus at the low baseline, while A2C augmented with TRT continues showing progress toward the higher reward associated with picking up the key. The same pattern holds when distractor gift rewards become larger: stronger immediate temptations further drown out the delayed credit signal, yet TRT still drives more reliable key acquisition. Finally, when distractor rewards have the same mean but higher variance, A2C again struggles, while TRT maintains an advantage, suggesting the approach is robust to noisy distractor outcomes.
In the Q&A, the distractor design is framed as a direct consequence of discounting and policy-gradient credit assignment: the agent quickly learns the actions that generate immediate reward during the distractor phase, and those rewards dominate the gradient updates. The discussion also notes that more advanced algorithms like PPO might learn faster overall due to sample efficiency, but TRT’s interaction with PPO wasn’t tested in these results. The project’s broader contribution is a modular architecture: attention-based identification of significant state-action pairs is separated into a classifier, making it easier to bolt TRT onto other reinforcement learning systems. The work is positioned as a heuristic built on earlier value-transport ideas, with future directions including testing in more complex environments and exploring beyond the current heuristic assumptions.
Cornell Notes
Long-delayed rewards often vanish under discounting, so standard reinforcement learning struggles to learn actions whose payoff arrives only at the end of an episode. Temporal Reward Transport (TRT) addresses this by (1) using an attention-based intention mechanism to locate the state-action pairs most associated with the eventual outcome, then (2) splicing distal rewards back onto those earlier pairs to amplify the learning signal. In a three-phase gridworld where picking up a key in phase one enables a large bonus in phase three, A2C alone plateaus at the low baseline when distractors become more time-consuming, more rewarding, or more variable. Adding TRT to A2C produces consistent learning progress toward the higher key-dependent reward. The modular design separates attention from the rest of the algorithm, making TRT easier to integrate elsewhere.
Why does standard reinforcement learning fail on tasks with delayed rewards?
What is Temporal Reward Transport (TRT), and how does it change learning?
How does TRT decide which state-action pairs are “significant”?
How does the distractor phase make the task harder than simply learning to interact with everything?
What experimental changes were used to test TRT’s robustness?
Why is the implementation described as modular, and why does that matter?
Review Questions
- In the key-and-goal setting, what specific mechanism in TRT counteracts the effect of discounting on early actions?
- How do changes to distractor time delay, reward size, and reward variance each alter the learning signal received by phase-one actions?
- What evidence from the attention heatmap and sanity check supports the claim that TRT is crediting the right state-action pairs?
Key Points
- 1
Standard reinforcement learning can struggle with long-delayed rewards because discounting sharply reduces the learning signal for early actions whose payoff arrives much later.
- 2
Temporal Reward Transport (TRT) improves credit assignment by splicing distal rewards back onto earlier, significant state-action pairs.
- 3
TRT uses an attention-based intention mechanism: a classifier assigns attention scores across episode frames to identify which moments matter most for the eventual outcome.
- 4
In a three-phase gridworld, A2C alone can plateau at a low baseline when distractors dominate, while A2C+TRT continues learning to pick up the key.
- 5
TRT’s advantage persists when distractor difficulty increases via longer distractor delays, larger immediate gift rewards, or higher distractor reward variance.
- 6
The distractor phase creates a strong immediate-reward gradient that can drown out delayed credit for key collection, making the task a direct test of long-horizon credit assignment.
- 7
The TRT implementation is modular, with attention handled by a separate classifier, enabling easier integration with other reinforcement learning approaches.