Looking For Grammar In All The Right Places | Alethea Power | OpenAI Scholars Demo Day 2020
Based on OpenAI's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Power treats interpretability as a safety and fairness tool, not just an academic exercise, because AI systems can amplify bias and enable harmful text generation.
Briefing
Alethea Power’s project targets a practical, high-stakes question: where inside GPT-2 does grammar information live, and how can that location be measured well enough to improve interpretability and safety. Power frames interpretability as “mind-reading” for neural networks—opening the model to see how it represents and processes information—because AI systems now shape daily life and can amplify bias, waste energy, and enable misuse. Her specific focus is grammar: understanding how GPT-2 handles English structure could help reduce harmful outputs, make models more efficient, and even support longer-term efforts to connect machine representations to human thought.
Power begins by contrasting traditional software with deep learning. In software engineering, humans write explicit logic from inputs to outputs. In deep learning, humans instead provide training data and mathematical objectives; the resulting “software” is harder to inspect because it’s encoded in parameters rather than readable code. She then motivates why interpretability matters personally and socially: airport scanning systems can flag transgender people for additional screening; other AI-driven systems (including those used in transportation) have been linked to higher risk for people of color. Better understanding of model internals, she argues, can reduce bias and improve efficiency by enabling smaller networks that do the same job with less compute.
To study grammar inside GPT-2, Power narrows the problem to a tractable slice: how GPT-2 represents English grammar. She uses GPT-2 (including a smaller variant that fits on a home GPU) and builds a “grammar modeling layer” on top of the transformer stack. Instead of predicting the next word, the modified model predicts grammatical annotations—three granularities: simple part of speech, detailed part of speech, and syntactic dependencies. She constructs datasets of 300,000 sentences each, tagged using spaCy, and trains the grammar layer as a probe for information available at different depths.
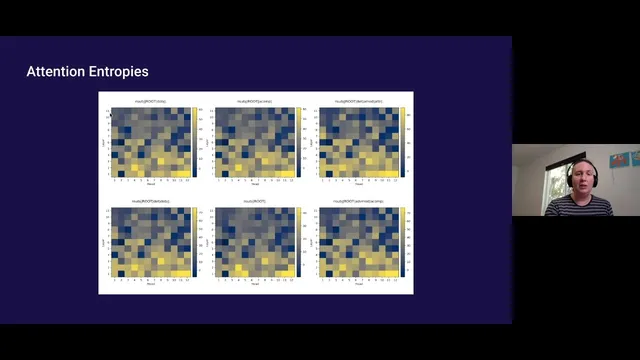
Her analysis uses attention-head behavior to infer how information is being mixed. She measures entropy of attention matrices across layers: higher entropy suggests more complex mixing of information across token positions. The entropy patterns show that lower layers perform more restructuring for the grammatical task than upper layers. She then tests where grammar becomes “readable” by training the probe on top of each layer and tracking performance (loss/score). Grammar tagging improves markedly from early layers and peaks around layers 5–6 for syntactic dependencies, while information about incoming tokens is strongest in lower layers and information about expected outgoing structure becomes more accessible higher up.
Power interprets this as information being “rotated” into an abstract space by attention heads—then “stretched” or “warped” so that grammatical features become linearly accessible at specific depths. To go further, she truncates GPT-2 to the top half and performs head-level ablations to identify which attention heads matter for each grammatical structure. For some structures, removing nearly all heads still preserves strong performance; for others, only a small subset is needed. She concludes that grammar is not uniformly distributed across the network: different grammatical phenomena rely on different sub-networks, and mapping those head dependencies could eventually enable more targeted interpretability and model understanding.
Cornell Notes
Alethea Power investigates where GPT-2 stores and makes accessible grammatical information. She replaces GPT-2’s next-token prediction head with a grammar prediction head that outputs parts of speech (simple and detailed) and syntactic dependencies, training on 300,000 spaCy-tagged sentences per task. By measuring attention entropy and training the grammar probe on top of each transformer layer, she finds that lower layers do more complex restructuring, while grammatical information becomes most linearly accessible around layers 5–6 for syntactic dependencies. She then truncates GPT-2 and uses attention-head ablations to identify which heads are essential, discovering that some sentence structures require very few—or even no—attention heads. The work suggests grammar is encoded in specific, reusable sub-networks rather than spread evenly across the model.
Why does Power treat interpretability as more than a curiosity, and why focus on grammar inside GPT-2?
How does Power modify GPT-2 to measure grammar information?
What does attention entropy reveal in her analysis?
How does she determine which layers make grammar most accessible?
What does head ablation show about how grammar is encoded?
Review Questions
- When Power replaces GPT-2’s next-token head with a grammar head, what exactly changes in the prediction target, and why does that make layer-wise probing possible?
- How do attention entropy results and probe performance peaks jointly support the claim that grammar information is processed differently across transformer depth?
- What does it mean, practically, that some grammatical structures require very few (or no) attention heads according to her ablation results?
Key Points
- 1
Power treats interpretability as a safety and fairness tool, not just an academic exercise, because AI systems can amplify bias and enable harmful text generation.
- 2
She probes GPT-2 grammar by swapping the next-token language modeling head for a grammar prediction head that outputs parts of speech and syntactic dependencies.
- 3
Using 300,000 spaCy-tagged sentences per grammar type, she trains probes at each transformer layer to measure where grammatical information becomes linearly accessible.
- 4
Attention entropy indicates that lower layers perform more complex token mixing for grammar, while probe peaks suggest the most usable grammatical representations appear around layers 5–6 for syntactic dependencies.
- 5
A “incoming vs outgoing” probe variant shifts the best layer upward (around layer 8), consistent with later layers being more aligned with generation of expected structure.
- 6
Attention-head ablations reveal that grammar can depend on small, structure-specific sub-networks rather than the entire attention stack.