Mamba sequence model - part 1
Based on West Coast Machine Learning's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Mamba targets the gap between efficient long-context models and Transformer-like content-based reasoning by making SSM parameters depend on the current input token.
Briefing
Mamba’s core pitch is that sequence models can match Transformer-quality results on language and other modalities while scaling linearly with sequence length—by replacing attention with “selective” structured state space models (SSMs). The central weakness targeted is content-based reasoning: many efficient SSM-style architectures struggle to change behavior based on which token appears, so they can’t reliably route information the way attention does. Mamba addresses this by making key SSM parameters depend on the current input token, enabling selective propagation or forgetting of information as the sequence unfolds.
The discussion anchors on the paper “Linear Time Sequence Modeling with Selective State Spaces” by Albert Gu and Tri Dao, which frames Transformers as the dominant architecture but highlights their quadratic cost on long contexts. Alternatives—sparse attention, linear attention variants, gated convolutions, recurrent models, and structured SSMs—aim to reduce compute, yet often underperform on important discrete modalities like language. The paper argues that the missing ingredient is a mechanism for content-based reasoning, especially in discrete token streams.
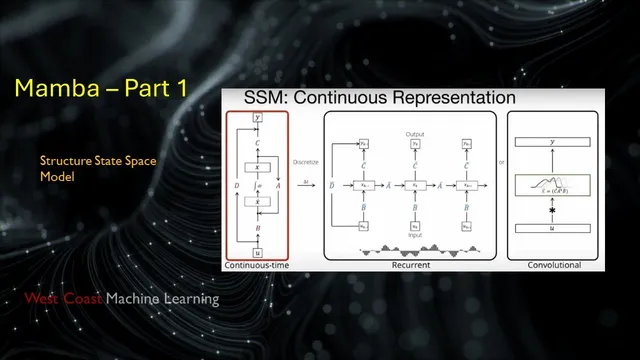
A key technical storyline runs through SSMs like S4 (Structured State Spaces), which build on earlier control-theory-inspired models. In continuous time, an SSM describes how a hidden state evolves under linear dynamics and produces outputs via linear projections. To use it for sequences, the model is discretized into an RNN-like recurrence and—crucially—can also be viewed as a convolution over the entire input sequence. That convolutional view enables efficient parallel training, while the recurrent view supports fast step-by-step inference.
However, naive SSM implementations run into two practical barriers: (1) if the state-transition matrix is randomly initialized, the model performs poorly on long-range benchmarks, and (2) computing the convolution filter directly is expensive because it involves repeated powers of the transition matrix, creating both numerical and runtime bottlenecks. S4’s solution is to hard-code a special structured form for the transition matrix (derived from “HiPPO” memory ideas using Legendre polynomial projections). This structure both stabilizes long-range behavior and enables fast algorithms for computing the convolution filter without the prohibitive cost.
Mamba builds on this foundation but changes the rules: it introduces selectivity so that SSM parameters become input-dependent, restoring the ability to react to content. The result is a model that can be implemented efficiently (including GPU-aware parallel algorithms) and that scales linearly in sequence length. Reported outcomes include strong performance on long-context benchmarks and cross-modality results; notably, a 2.8B-parameter Mamba model outperforms same-size Transformers and matches Transformers trained at roughly twice the parameter count, using training recipes considered best practice for Transformers. The broader takeaway is that structured state spaces—once made selective and hardware-efficient—can become a serious alternative to attention for long sequences, and the field is now watching whether scaling Mamba beyond current experimental sizes will keep closing the gap.
Cornell Notes
Mamba’s approach to long-sequence modeling replaces attention with selective structured state space models (SSMs). The motivation is that many efficient SSMs lack content-based reasoning—behavior that changes depending on which token appears—so they underperform on language. The background centers on S4, which makes SSMs practical by using a special HiPPO/Legendre-based structure for the state-transition matrix, stabilizing long-range dependencies and enabling fast computation of the equivalent convolution filter. Mamba then adds “selectivity” by making important SSM parameters depend on the current input token, restoring token-conditioned behavior while keeping linear-time scaling. This combination aims to deliver Transformer-like quality with much better long-context efficiency.
Why do Transformers struggle with long sequences, and what alternatives try to fix that?
What is the “content-based reasoning” weakness attributed to many SSM-style models?
How does S4 make state space models trainable and efficient for long contexts?
Why can an SSM be viewed as both an RNN and a convolution?
What changes in Mamba relative to S4?
What performance claim is highlighted for Mamba at moderate scale?
Review Questions
- How do the three representations of an SSM (continuous-time, recurrent/discretized, and convolutional) relate to training vs inference efficiency?
- What specific role does the HiPPO/Legendre-based structure of the transition matrix play in S4’s ability to handle long-range dependencies?
- Why does making SSM parameters input-dependent (selectivity) help with content-based reasoning in discrete modalities like language?
Key Points
- 1
Mamba targets the gap between efficient long-context models and Transformer-like content-based reasoning by making SSM parameters depend on the current input token.
- 2
Structured state space models can be interpreted as RNNs (for stepwise inference) and as convolutions (for parallel training), after discretization/unrolling.
- 3
S4’s practical success comes from hard-coding a special structured transition matrix (HiPPO/Legendre-based) to stabilize long-range behavior and avoid expensive naive convolution computation.
- 4
Naively computing the convolution filter for an SSM is costly because it involves repeated powers of the transition matrix, creating runtime and numerical issues.
- 5
Mamba builds on S4 but adds “selective” parameterization plus hardware-aware parallel algorithms to keep linear-time scaling while improving language performance.
- 6
Reported results emphasize that a 2.8B-parameter Mamba model can beat same-size Transformers and match roughly 2×-size Transformers using strong Transformer training recipes.