Midjourney has COMPETITION & it's FREE/Open Source - Deepfloyd IF AI Art Model
Based on MattVidPro's video on YouTube. If you like this content, support the original creators by watching, liking and subscribing to their content.
Deep Floyd’s IF is positioned as a fully open-source text-to-image model, with GitHub code available and model weights released shortly after.
Briefing
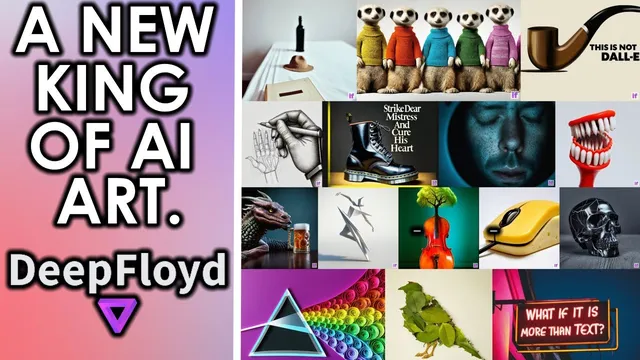
Deep Floyd’s IF is landing as a fully open-source, high-resolution text-to-image model—complete with code on GitHub and (soon after) model weights released—positioning it as a serious alternative to closed systems like Midjourney. The headline feature isn’t just image quality; it’s unusually strong text rendering. Examples shown across signs, posters, logos, and even prompt-driven objects repeatedly produce legible spelling and prompt-specific wording, something the transcript contrasts directly with Midjourney’s weaker performance on text.
The model’s release timing matters because open-source access typically accelerates iteration. The discussion frames IF as “stable diffusion level of access,” arguing that community fine-tuning, new pipelines, and derivative models will compound improvements over time. That expectation is reinforced by the modular design and the practical deployment options: the code is available, the ecosystem integrates with Hugging Face tooling (including diffusers and Spaces), and a Google Colab notebook and local-running instructions are referenced. There’s also a license requirement for using it on Hugging Face, but the overall message is that creators can experiment without waiting for a proprietary API.
On capability, IF is described as high-fidelity and high-resolution through a cascaded pipeline. The system generates an initial 64×64 image from text, then upscales to 256×256 and finally to 1024×1024 using two super-resolution stages. A frozen T5 Transformer text encoder extracts text embeddings, which feed into a unit architecture enhanced with cross-attention and attention pooling. The transcript also cites benchmark claims: a zero-shot FID score of 6.66 on the COCO dataset, plus comparisons claiming it beats multiple named models on benchmarks (including Imogen, Dolly, and others), while avoiding a direct claim of beating Midjourney.
Hardware requirements are presented as a key adoption lever. The base 64×64 model and 256×256 upscaling can run on consumer GPUs with 16GB VRAM, while reaching the top 1024×1024 stage is said to require about 24GB VRAM. The transcript gives an example of an RTX 4090 as a way to run the full resolution at home, and notes that the model can be used in environments like Kaggle and Jupiter notebooks.
Beyond text-to-image, the model is portrayed as versatile: it supports style transfer (changing the look while preserving composition), inpainting (adding elements like a hat with convincing integration), and super-resolution workflows that recover detail from low-resolution inputs. The examples range from photorealistic scenes—rusty street signs, “4K DSLR” animals, and product-like food images—to highly specific prompts involving logos, named characters, and stylized objects. Even when failures occur (especially spelling mistakes), the transcript argues the open-source nature will help address weaknesses through fine-tuning and cheaper optimization.
Overall, IF’s combination of open release, modular high-resolution pipeline, and strong text control is positioned as a competitive shift in the text-to-image landscape—one that could reshape how creators choose between open and closed models, at least until a direct head-to-head comparison with Midjourney V5 is done.
Cornell Notes
Deep Floyd’s IF is released as an open-source text-to-image model with code on GitHub and model weights released shortly after. Its standout strength in the examples shown is legible, prompt-specific text—on signs, posters, logos, and objects—paired with high-fidelity, photorealistic outputs. The architecture is cascaded: it generates 64×64 images from text, then upscales to 256×256 and 1024×1024 using two super-resolution stages, with a frozen T5 Transformer text encoder feeding a cross-attention-based unit architecture. The model is designed to run on consumer hardware for lower stages (16GB VRAM for base/upscaling) and higher resolution with more VRAM (about 24GB). Open access is expected to accelerate community improvements through fine-tuning and new tools.
What makes Deep Floyd’s IF different from many competing image generators in the transcript’s examples?
How does IF produce high-resolution images, and what are the key stages?
What role does the T5 Transformer play in IF?
What hardware constraints are mentioned for running IF at different resolutions?
Besides text-to-image, what additional functions does IF support in the transcript?
Why does open-source availability matter for IF’s expected progress?
Review Questions
- What architectural components enable IF to translate text prompts into images, and how does the cascaded upscaling pipeline work?
- Which IF capabilities in the transcript go beyond text-to-image, and what practical use-cases do they suggest?
- How do the stated VRAM requirements influence who can run IF locally at 1024×1024 resolution?
Key Points
- 1
Deep Floyd’s IF is positioned as a fully open-source text-to-image model, with GitHub code available and model weights released shortly after.
- 2
The transcript emphasizes unusually strong spelling and prompt-specific text rendering across signs, posters, and logos.
- 3
IF’s generation pipeline is cascaded: 64×64 base generation followed by 256×256 and 1024×1024 super-resolution stages.
- 4
A frozen T5 Transformer text encoder produces embeddings that feed a cross-attention-based unit architecture for image synthesis.
- 5
Consumer hardware can run lower-resolution stages (around 16GB VRAM), while full 1024×1024 output is described as requiring roughly 24GB VRAM.
- 6
IF is presented as more than text-to-image, including style transfer, inpainting, and super-resolution workflows.
- 7
Open-source access is expected to accelerate community fine-tuning and optimization, potentially improving weaknesses like occasional spelling failures.